Materialization#
Querona supports multiple modes of materialization of your data, configured per view.
Materialization means that for query processing, Querona uses data from the materialized copy instead of reaching out to the data source. It is especially efficient to materialize data that is time and resource consuming to gather. On the other hand, materialization means that data is only as current as of the last load.
Newly configured materialization is not initialized. Depending on the mode used, materialization uses one of the following:
lazy, initialized at first call for data,
on-demand, uses a scheduled job or manual stored procedure call.
A partition is a physical division of data into distinct, independent parts using some consistent rule (partitioning key). In other words, data is stored and processed in blocks called partitions.
Partitioning is one of the most widely used techniques to optimize physical data layout. It provides a coarse-grained index for skipping unnecessary data reads when queries have predicates on the partitioned columns.
Partitioning may substantially increase performance when:
Processing can skip partitions; for example, billing data is partitioned by the country code, and query requires processing data for one particular country. In that case, only one partition will be processed.
Processing can be parallelized; for example, query requires grouping by country, and that can be done in parallel for each country partition.
The number of distinct values in each column is less than tens of thousands.
Basic usage#
The newly configured view materialization is not initialized - no data copy exists.
In-memory materialization is populated on the first usage (lazy initialization). To make sure view is materialized, consult ‘Cached’ column on ‘Tables & views’ page.
The following scenario assumes that Apache Spark is used as a virtual database back-end.
Go to , select database and then the view for which you wish to configure materialization.
While in view details, go to tab.
Click Edit and select caching mode, then partitioning mode if necessary or ‘No partitioning’.
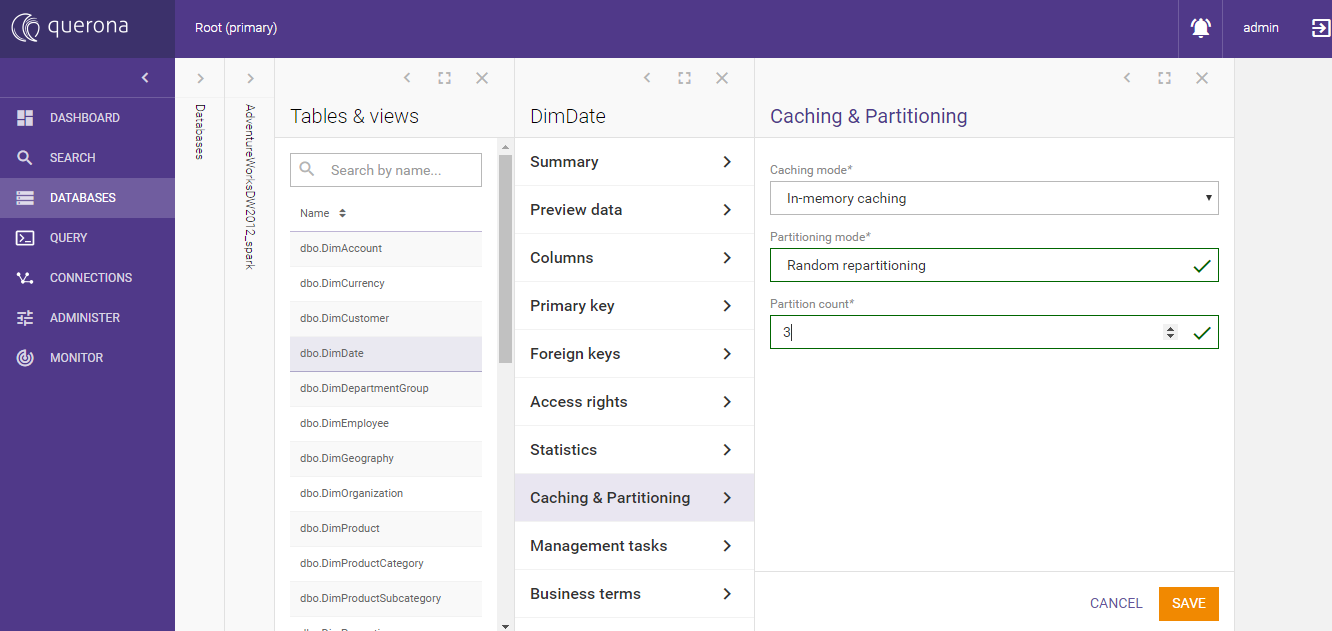
Click Save. Materialization is now configured, but not yet populated.
Go to Management Tasks tab.
If persistent materialization was selected, click Rebuild materialized view. If in-memory materialization was selected, click Refresh Spark’s memory cache, then click Run once button, to populate it. Strictly speaking, the in-memory copy would be reloaded on the first usage if it was not loaded previously.
After a while, Querona will confirm that view was materialized.
You can review materialization state on Tables & views tab. Optionally, instead of manually materializing the view, you can set up a job that will materialize the view according to the selected schedule.
Instead of clicking Run once as in 6, click Define job.
After the job is created, go to Schedules tab.
Click Add schedule and select one of the available schedules. The selected schedule will appear on the list.
The materialized view will be automatically refreshed according to the selected schedule.
You can also refresh a persistent materialized view from SQL, instead of clicking Rebuild materialized view:
EXEC qua_refresh_persistent_cache 'MyVdb.dbo.MyView';
It refreshes the view using its configured strategy (for example, incremental) and does not apply to in-memory materialization modes. See qua_refresh_persistent_cache. Configuring the cache mode itself is done in the GUI, as above.
Materialization strategies#
Materialization is available for views defined in virtual databases, which as a back-end use a supported database engine. In-memory materialization modes are available only for engines that can hold data in memory (eg. Apache Spark.)
Note
When populating a materialized view, Querona writes to the target using the most efficient method available for
that engine — typically bulk loading (for example, BULK INSERT).
In-memory caching#
Data is stored in RAM. Access times may be better, compared to the persistent materialization. On the other hand, when the Spark process exits, the in-memory copy is lost and will be initialized again on first use.
Persistent caching - one table#
Data is stored in a single table. Table format may differ depending on what data processing system was used as virtual database back-end.
Persistent caching - two rotated tables#
Working set of data is stored on disk in a single table, but there is also second ‘buffer’ table that is used as insert target when the data is reloaded. When reloading data, _A and _B tables are both present on disk doubling peak storage required. On the other hand, materialization does not interfere with current queries.
Persistent caching - one table, in-memory#
Data is stored both in-memory and on-disk. When Spark is restarted, the materialized data can be loaded from the local storage.
Persistent caching - two rotated tables, in-memory#
The combination of in-memory and persistent rotated materialization. It takes most space, both disk, and RAM, but potentially offers the best performance of in-memory processing while still being persistent and able to reload in the background.
In the case of Spark, table compression may be in effect. Disk and RAM representations may differ.
Index propagation#
When the given view has an index defined, the materialization mode is set to Persistent, and the underlying provider supports creating indexes, then the index is created and built on the physical data store. This might significantly speed up query execution.
A new index can be defined as well, but propagating it to the underlying provider requires the materialized view to be recreated.
Note
For more information about indexes see Indexes.
Incremental loading#
A materialized view can be refreshed in two ways:
Full load — the materialized view is rebuilt from the source on each refresh (optionally using two rotated tables so running queries are not interrupted; see Materialization strategies above).
Incremental load — only rows that changed at the source since the last load are applied, which is far cheaper for large, slowly-changing data sets.
Incremental loading from Microsoft SQL Server#
Querona can read incrementally from a Microsoft SQL Server source using its Change Tracking feature. Change Tracking must be enabled on the source SQL Server instance and on the tables involved.
Querona tracks the change window automatically. If the change window is missed — for example, the source pruned its change information before the next load ran — Querona falls back to a full reload of the view to reinitialize it, returning the materialized view to a correct, consistent state.
Enabling Change Tracking on SQL Server#
Querona is a client of SQL Server Change Tracking — it reads the change feed but does not configure it. A SQL Server administrator enables it once on the source, in three steps. Run the following on the source SQL Server.
1. Enable Change Tracking on the database. CHANGE_RETENTION controls how long the source keeps
its change information — set it longer than the interval between incremental loads, otherwise Querona
can miss the window and fall back to a full reload (see above). AUTO_CLEANUP lets SQL Server purge
information older than the retention period.
ALTER DATABASE [SourceDb]
SET CHANGE_TRACKING = ON
(CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON);
2. Enable Change Tracking on each source table. Enable it on every table the materialized view reads from. Each such table must have a primary key — Change Tracking identifies changed rows by their key.
ALTER TABLE [dbo].[SourceTable] ENABLE CHANGE_TRACKING;
3. Grant the Querona login permission to read the changes. The login Querona connects to
the source with needs VIEW CHANGE TRACKING on each tracked table; without it, change queries fail.
GRANT VIEW CHANGE TRACKING ON [dbo].[SourceTable] TO [querona_login];
To confirm what is enabled, query sys.change_tracking_databases and sys.change_tracking_tables
on the source. For the complete feature reference, see Microsoft’s Change Tracking documentation.
Partitioning#
Partitioning is only available for views materialized using data processing systems that support it, eg. Apache Spark. Available partitioning modes depend on selected materialization strategy.
Note
Take into account that creating too many partitions (for 10x or 100x times more than available cores) can severely hinder performance. On the other hand, too little partitions (for example 1/10th of available cores) can limit potential parallel processing.
In-memory partitioning modes#
Partitioning mode |
Description |
|---|---|
Random repartitioning |
Rows will be randomly allocated to all partitions. |
Linear column partitioning |
Rows will be allocated to partitions based on the selected column value. The number of partitions and min/max values of supported partition keys is configurable. |
Column value based |
Instead of relying on auto-division of rows, you specify particular values of the partition key for each partition. |
Column value ranges based |
This mode is extended version of column value based mode. Instead of selecting a single value for each partition, you can choose to use the whole range. |
Predicate-based |
Most flexible, but also most complicated mode. For each partition, you provide handwritten SQL predicate using views columns. Rows that satisfy predicate will fall into given partition. Note that user is responsible for making sure predicates are valid Spark SQL and are useful predicates for partitioning. |
Persistent caching#
You select set of columns over which partitioning will be enforced.
Advanced configuration#
The advanced configuration allows users to fine-tune the settings of the table that stores the data supporting the view.
Table storage format#
The table storage format controls the physical format of the table. The following modes are supported for Spark:
Format |
Description |
|---|---|
Default |
The format of a table is taken from the default configuration of the Spark instance used. Usually ORC or Parquet. |
Parquet |
Parquet, an open-source file format for Hadoop stores nested data structures in a flat columnar format. Compared to a traditional approach where data is stored in a row-oriented approach, parquet is more efficient in terms of storage and performance. It is especially good for queries that read particular columns from a wide (with many columns) table since only needed columns are read and IO is minimized. |
ORC |
The Optimized Row Columnar (ORC) file format provides a highly efficient way to store data. It was designed to overcome the limitations of other file formats. It ideally stores data compact and enables skipping over irrelevant parts without the need for large, complex, or manually maintained indices. The ORC file format addresses all of these issues. ORC stores collections of rows in one file and within the collection the row data is stored in a columnar format. |
JSON |
JavaScript Object Notation (JSON) is an open standard file format, and data interchange format, that uses human-readable text to store and transmit data objects consisting of attribute-value pairs and array data types (or any other serializable value). |
CSV |
A comma-separated values (CSV) file is a delimited text file that usually uses a comma to separate values. Each line of the file is a data record. Each record consists of one or more fields, separated by a delimiter. |
Delta |
As of Spark v3, the Delta format is supported. Delta Lake is an open-source storage layer that brings ACID transactions to Apache Spark. |
Parquet settings#
The following Parquet-specific settings are supported when using Parquet format:
Key |
Default value |
Setting Notes |
|---|---|---|
compression |
snappy |
Compression codec to use when saving to file. This can be one of the known case-insensitive shorten names(none, uncompressed, snappy, gzip, lzo, brotli, lz4, and zstd). |
ORC settings#
The following ORC-specific settings are supported when using ORC format:
Key |
Default value |
Setting Notes |
|---|---|---|
orc.compress |
ZLIB |
Compression type (NONE, ZLIB, SNAPPY, LZO). |
orc.compress.size |
262,144 |
Number of bytes in each compression block. |
orc.stripe.size |
268,435,456 |
Number of bytes in each stripe. |
orc.row.index.stride |
10,000 |
Number of rows between index entries (>= 1,000). |
orc.create.index |
true |
Sets whether to create row indexes. |
orc.bloom.filter.columns |
not set |
Comma-separated list of column names for which a Bloom filter must be created. |
orc.bloom.filter.fpp |
0.05 |
False positive probability for a Bloom filter. Must be greater than 0.0 and less than 1.0. |
JSON settings#
The following JSON-specific settings are supported when using JSON format:
Setting |
Default value |
Setting Notes |
|---|---|---|
compression |
null |
Compression codec to use when saving to file. This can be one of the known case-insensitive shorten names (none, bzip2, gzip, lz4, snappy and deflate). |
dateFormat |
yyyy-MM-dd |
Sets the string that indicates a date format. Custom date formats follow the formats at Datetime Patterns. This applies to date type. |
timestampFormat |
yyyy-MM-dd’T’HH:mm:ss[.SSS][XXX] |
Sets the string that indicates a timestamp format. Custom date formats follow the formats at Datetime Patterns. This applies to timestamp type. |
encoding |
not set |
Specifies encoding (charset) of saved json files. If it is not set, the UTF-8 charset will be used. |
lineSep |
\n |
Defines the line separator that should be used for writing. |
ignoreNullFields |
true |
Whether to ignore null fields when generating JSON objects. |
CSV settings#
The following CSV-specific settings are supported when using CSV format:
Setting |
Default value |
Setting Notes |
|---|---|---|
sep |
, |
Sets a single character as a separator for each field and value. |
quote |
“ |
Sets a single character used for escaping quoted values where the separator can be part of the value. If an empty string is set, it uses u0000 (null character). |
escape |
\ |
Sets a single character used for escaping quotes inside an already quoted value. |
charToEscapeQuoteEscaping |
escape or 0 |
Sets a single character used for escaping the escape for the quote character. The default value is escape character when escape and quote characters are different, 0 otherwise. |
escapeQuotes |
true |
A flag indicating whether values containing quotes should always be enclosed in quotes. Default is to escape all values containing a quote character. |
quoteAll |
false |
A flag indicating whether all values should always be enclosed in quotes. Default is to only escape values containing a quote character. |
header |
false |
Writes the names of columns as the first line. |
nullValue |
empty string |
Sets the string representation of a null value. |
emptyValue |
“” |
Sets the string representation of an empty value. |
encoding |
not set |
Specifies encoding (charset) of saved csv files. If it is not set, the UTF-8 charset will be used. |
compression |
null |
Compression codec to use when saving to file. This can be one of the known case-insensitive shorten names (none, bzip2, gzip, lz4, snappy and deflate). |
dateFormat |
yyyy-MM-dd |
Sets the string that indicates a date format. Custom date formats follow the formats at Datetime Patterns. This applies to date type. |
timestampFormat |
yyyy-MM-dd’T’HH:mm:ss[.SSS][XXX] |
Sets the string that indicates a timestamp format. Custom date formats follow the formats at Datetime Patterns. This applies to timestamp type. |
ignoreLeadingWhiteSpace |
true |
A flag indicating whether or not leading whitespaces from values being written should be skipped. |
ignoreTrailingWhiteSpace |
true |
A flag indicating defines whether or not trailing whitespaces from values being written should be skipped. |
lineSep |
n |
Defines the line separator that should be used for writing. Maximum length is 1 character. |