Connection configuration#
For general information regarding connections see Create a connection.
When adding a new connection to Spark, the following parameters apply:
Parameter |
Description |
Default value |
|---|---|---|
Name |
A friendly name of the connection e.g. Local Spark 3.0 |
|
Host:Port |
A comma-separated list of server:port pairs to connect to. For local instance use localhost:port. |
localhost:8400 |
Protocol |
The protocol that the driver will use to exchange data with Querona. Possible values: Thrift |
Thrift |
Spark dialect |
(= protocol version). The dialect version used to communicate with the driver. Possible values: 3.0, 4.0 |
|
Driver API key |
The security key used to authenticate requests incoming from Querona. Using the default value is highly NOT recommended. |
querona-key |
Username |
The account to be used for authenticating reverse connections from the driver |
|
Password |
The password for the account above |
|
Default database |
The database used to store materialized view data |
|
Reverse connection host address |
The address under which Querona can be reached by the driver. For local instance use localhost |
|
Node connection timeout |
The timeout used for waiting for each cluster node to respond. |
10s |
Cluster initialization timeout |
The timeout given for the instance to initialize when doing the initial request |
30s |
Frame size |
Frame size used when retrieving query results from Spark |
16777216 bytes |
Target partition size |
Defines the target size of partitions. |
128000000 bytes |
Max partitions for auto repartitioning |
Defines the upper limit for the number of partitions to be created. |
256 |
Note
When JOIN queries are pushed-down to execute on Spark, the data from the original database has to be copied to Spark. Querona registers external data sources as JDBC data frames, optionally applying repartition(n) function. If the data frame is too large it has to be broken into smaller chunks of size defined by Target partition size.
Scheduler pools#
To learn about Spark scheduler pools in general, please consult Spark Job Scheduling.
Scheduler pools describe relative part of cluster’s resources that will be assigned to process a given task. Querona’s Spark connections support the following scheduler pools:
default - scheduler pool used when no scheduler pool was selected explicitly
ETL - scheduler pool used by materialization jobs, and executes jobs in FIFO order
S, M, L, XL - 4 pools that user can specify for their queries with ascending allocation of resources
To specify pool to be used for given query use the OPTION clause. For example:
SELECT * FROM Table OPTION(POOL 'XL')]
or
INSERT INTO TABLE(COLUMN) select 1 OPTION(POOL 'S')
Exact configuration values for each scheduler pool can be reviewed and configured on Spark connection screen:
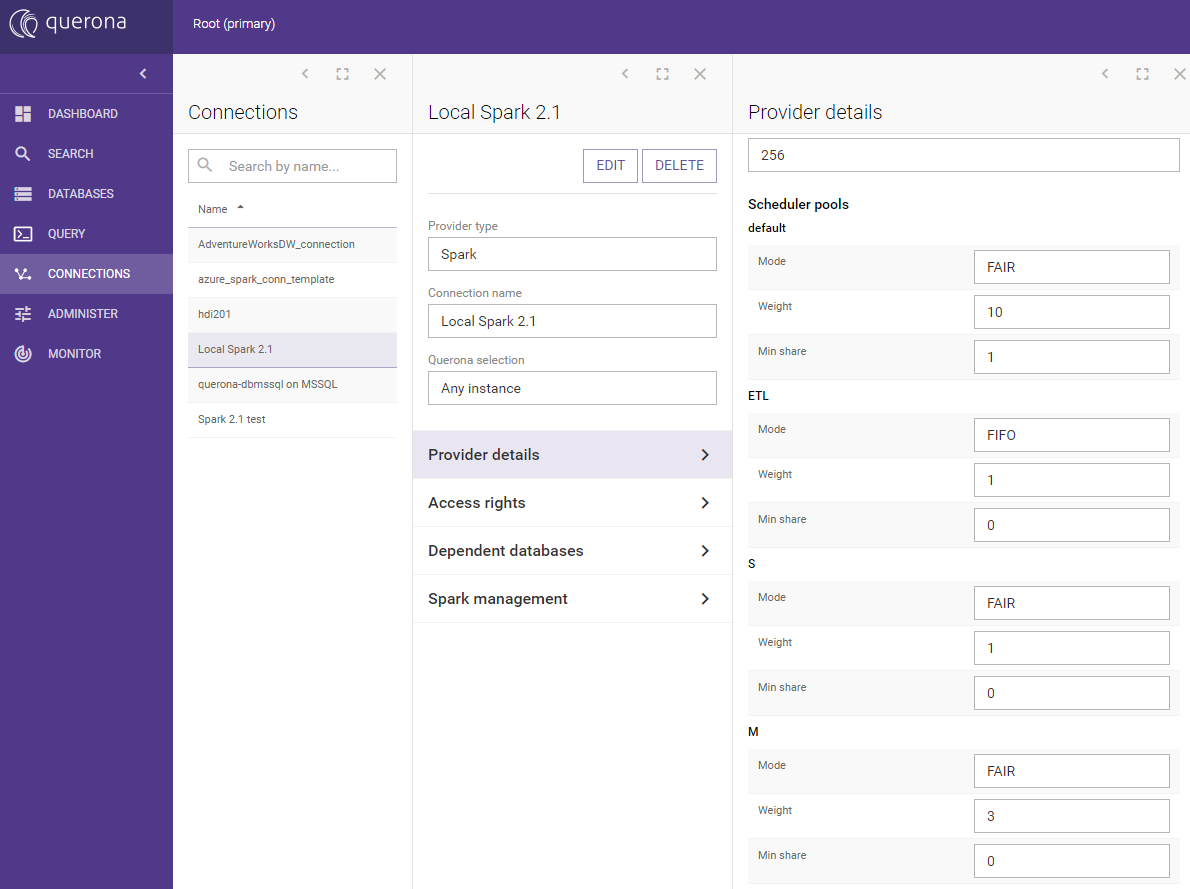
The pool properties are as follows:
Parameter |
Description |
|---|---|
Mode |
FIFO means tasks are queued one after the other. FAIR means that tasks can run in parallel and share resources. |
Weight |
Decides how much of cluster’s resources will this pool get relative to other pools. |
Min share |
Share of cluster’s resources assigned by FAIR scheduler (if possible) before allocation of rest of resources takes place. |
You can review pools used by spark for each query in Spark’s admin portal, just go to tab ‘Stages’:
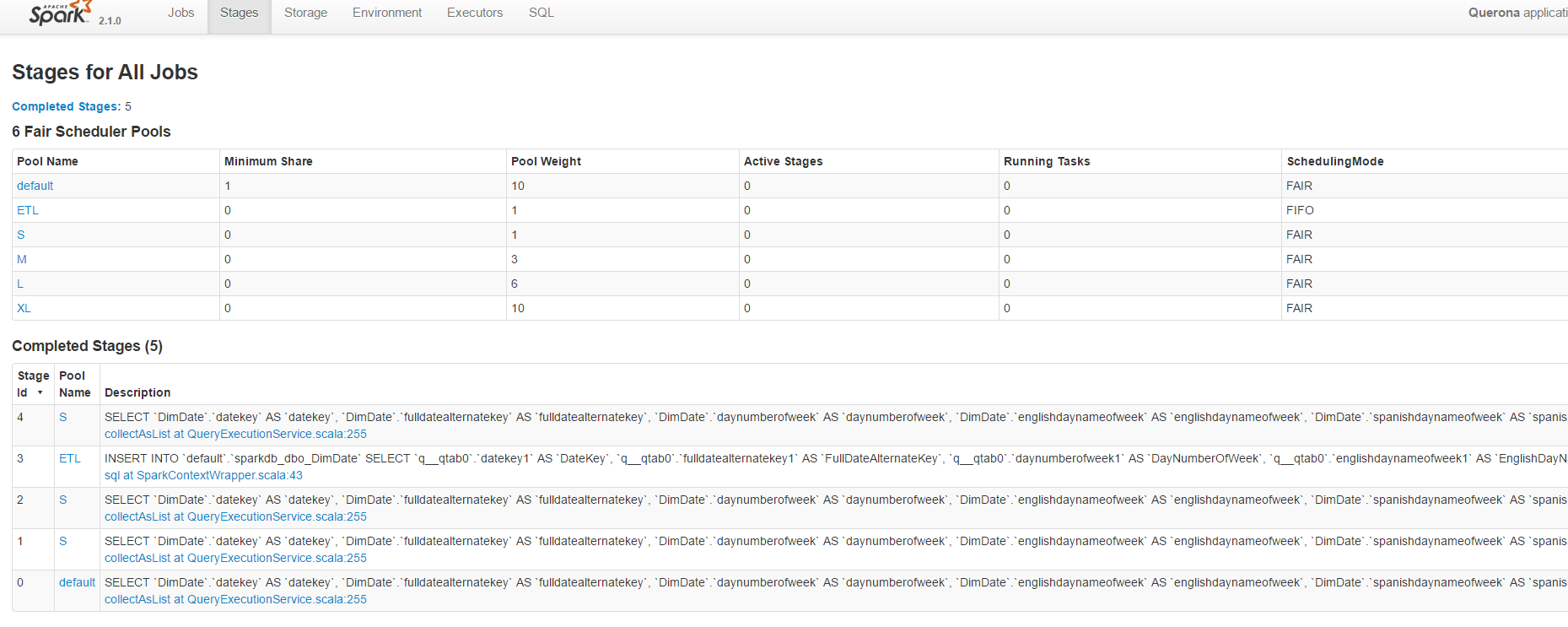
Spark variables#
Any properties prefixed with spark can be defined in this section and will be used when creating a new Spark context. The notable parameters are:
Parameter |
Description |
Default value |
|---|---|---|
spark.ui.port |
The Spark UI port |
4041 |
spark.local.dir |
The local working directory of Spark |
C:\ProgramData\Querona\tmp |
Hive configuration#
Internally Spark uses part of the Hive functionality. The important property is the warehouse directory which is a file system folder used as physical data storage.
Depending on the version of Spark used, this parameter is set by either/or hive.metastore.warehouse.dir and spark.sql.warehouse.dir. These values are set in the config files but can be passed on the connection level as well.
We highly recommend to always consult the documentation of Spark to make sure the right values are set. Excerpt from the Apache Spark v2.2 documentation:
Note
Note that the hive.metastore.warehouse.dir property in hive-site.xml is deprecated since Spark 2.0.0. Instead, use spark.sql.warehouse.dir to specify the default location of the database in a warehouse. You may need to grant write privilege to the user who starts the Spark application.
For the managed Spark instance, the following Hive parameters may need to be configured:
Parameter |
Description |
Default value |
|---|---|---|
javax.jdo.option.ConnectionURL |
JDBC connection string to the Hive metastore |
jdbc:sqlserver://localhost; databaseName=SparkMetastore; |
javax.jdo.option.ConnectionUserName |
JDBC login to Hive metastore |
|
javax.jdo.option.ConnectionPassword |
JDBC password to Hive metastore |
|
hive.exec.scratchdir |
C:/ProgramData/Querona/tmp/hive |
Hive tmp folder |
Connection test and Spark validation#
Once configured the Test Connection button can be used to verify whether the instance is responsive. Note, that this only test if the given driver instance responds to incoming connections. To fully test the configuration, the following steps are one of the methods to trigger and check Spark initialization:
Navigate to and create a new database named “spark-test-db” linked to the newly created connection
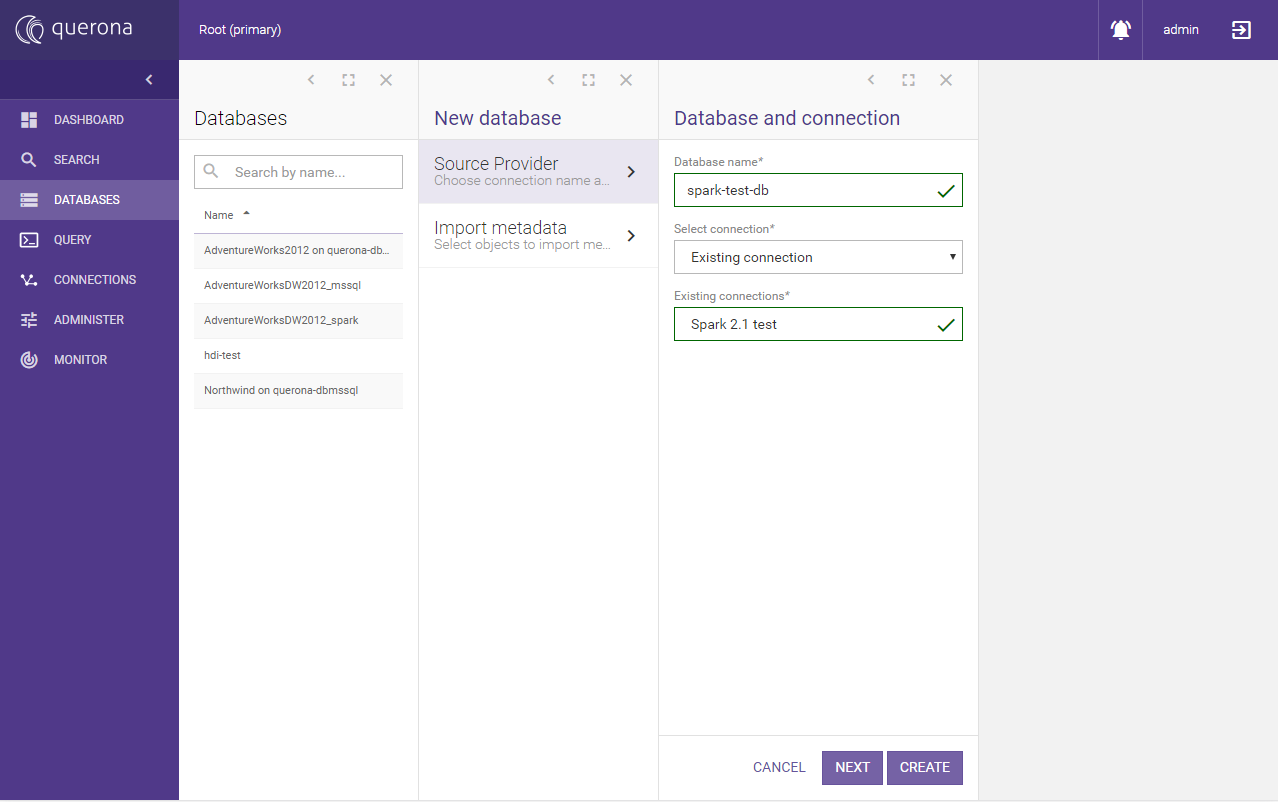
On the newly created database add new view of type Custom SQL named “test_view”:
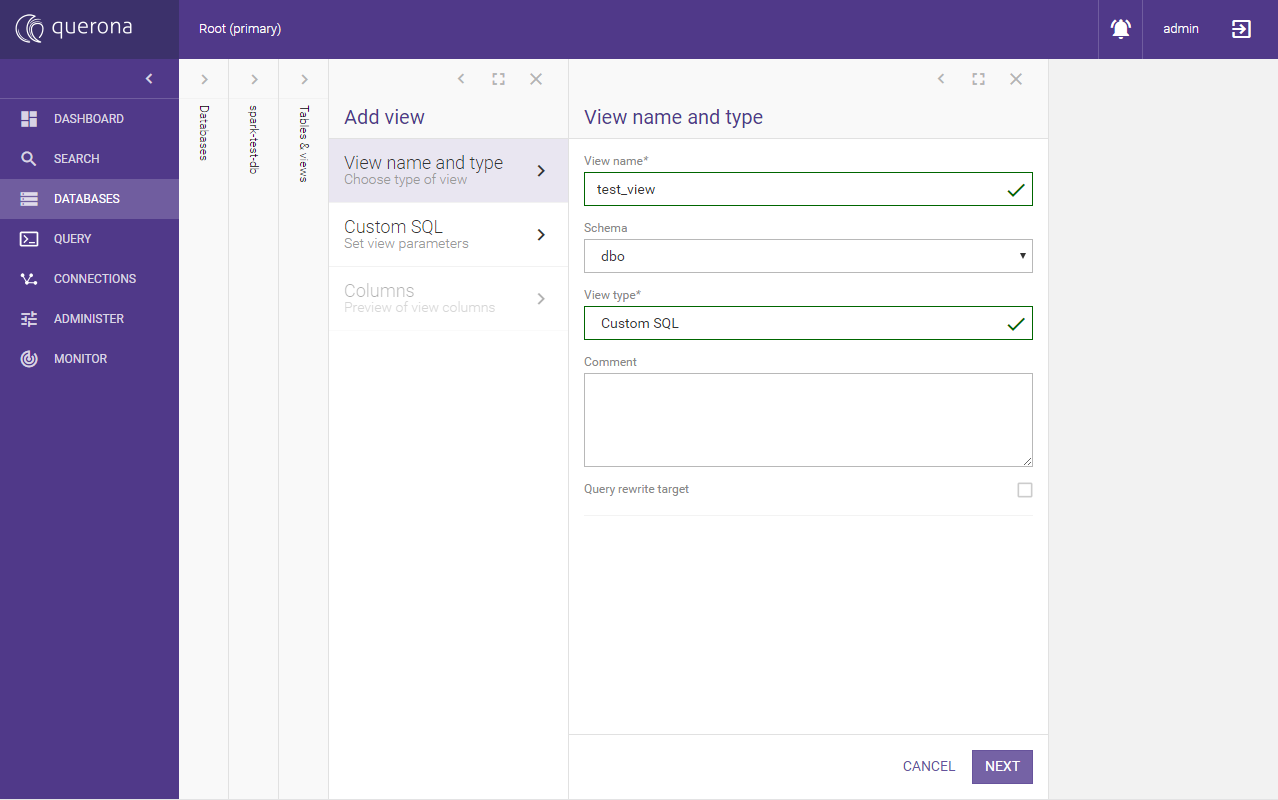
On the next screen type select 1 as col; and click Parse
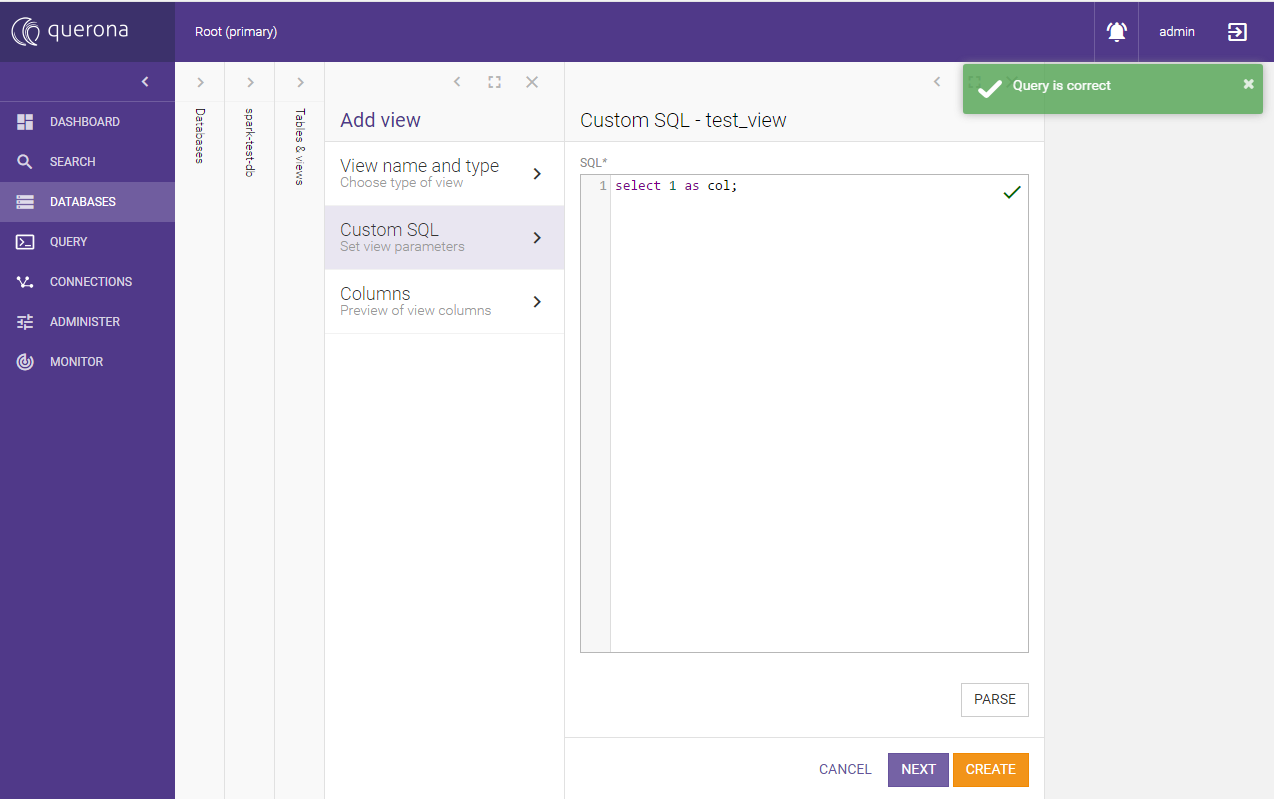
Finish creating the view
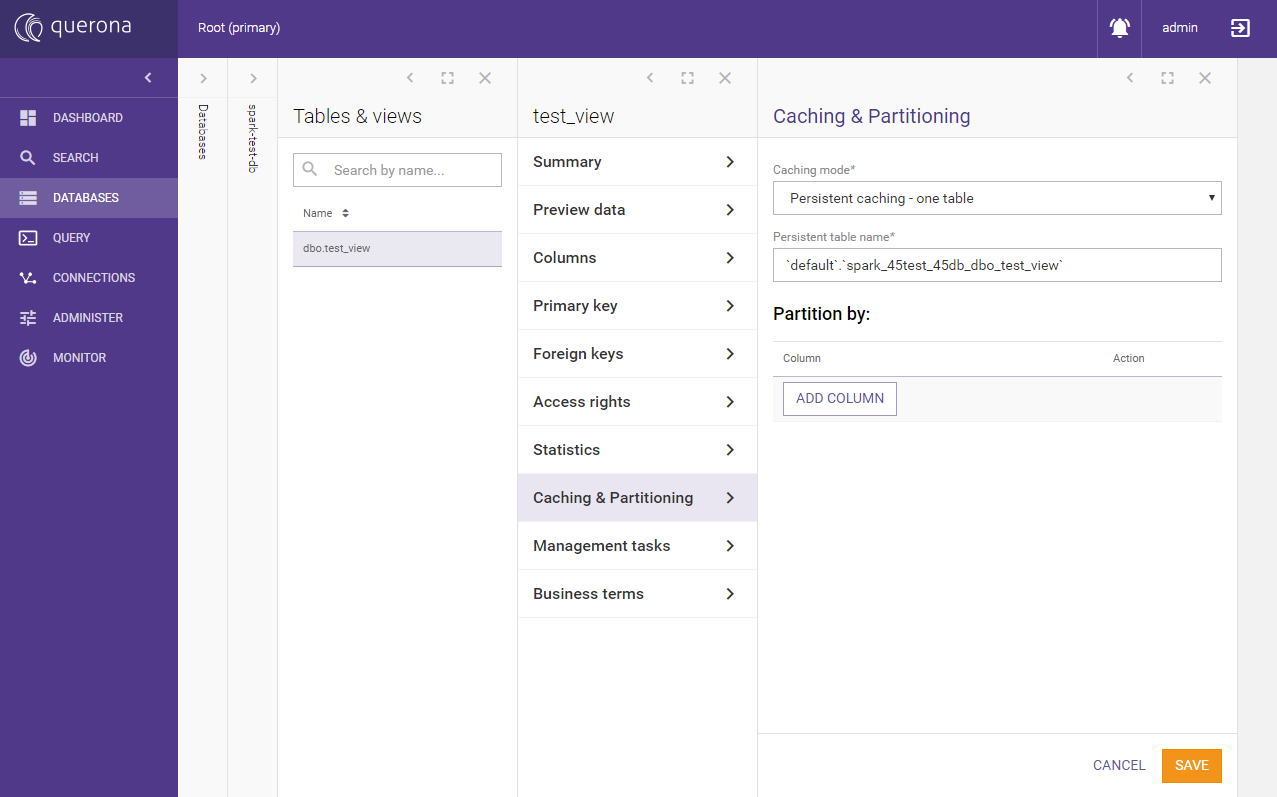
Click the view on the list and go to Caching and Partitioning, click Edit
Set Caching mode to Persistent caching - one table and Save
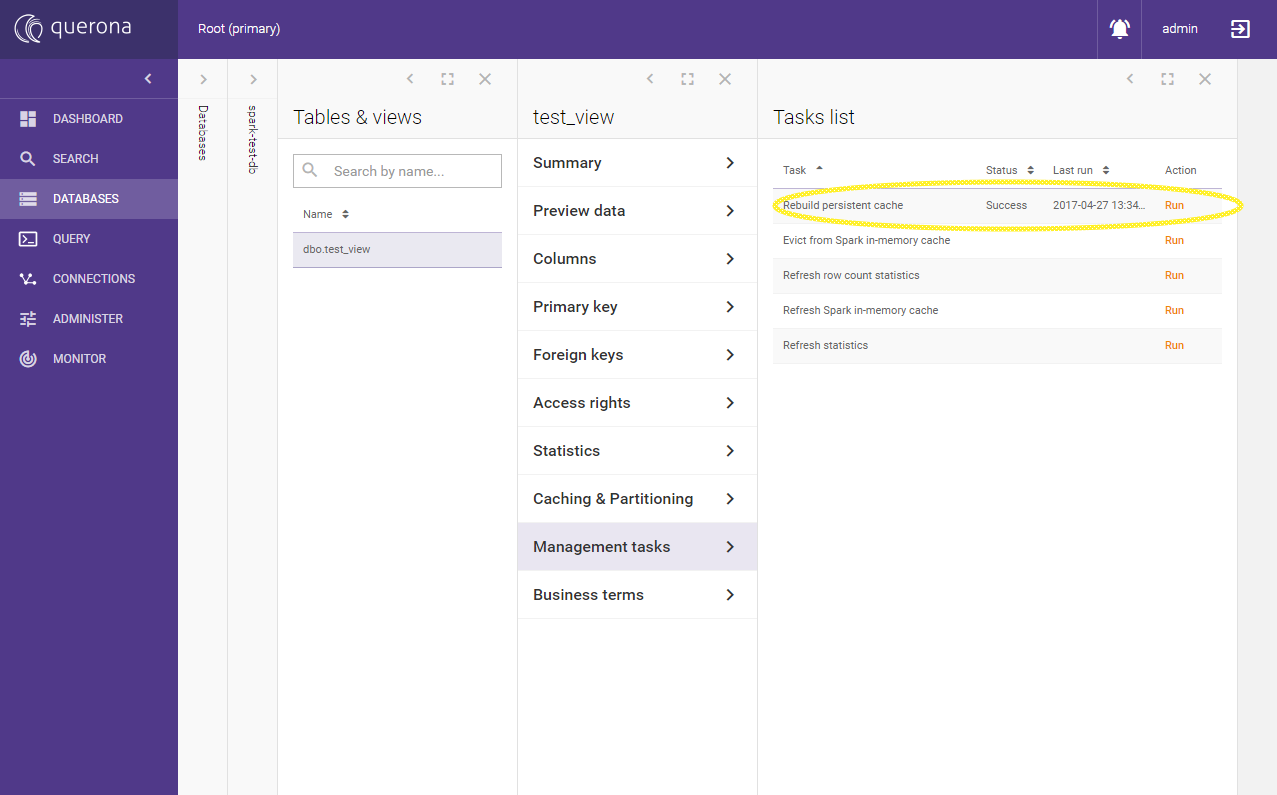
Go to Management tasks and run Rebuild persistent cache task
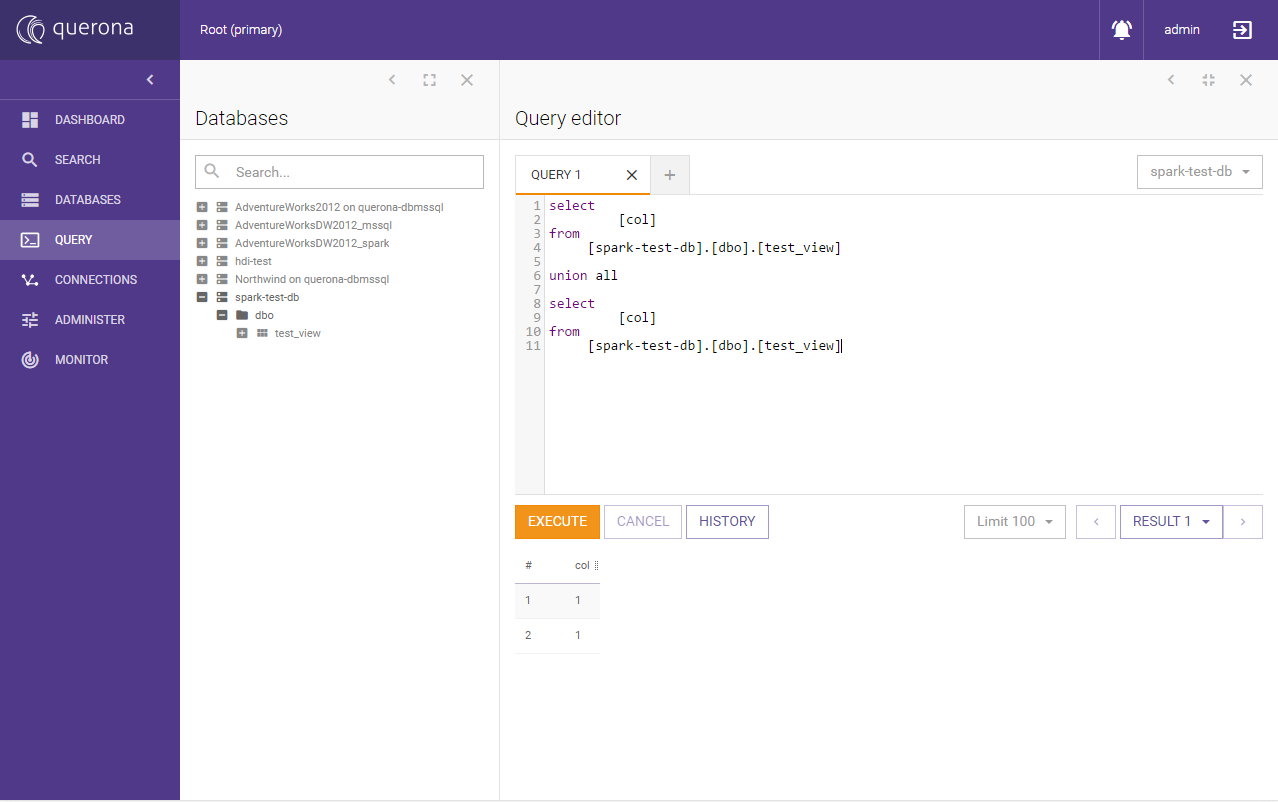
Go to query editor and run the following query on the Spark database:
select [col]
from [spark-test-db].[dbo].[test_view]
union all
select [col]
from [spark-test-db].[dbo].[test_view]
The result should look more or less like this:
These actions should force Spark to initialized. To verify it change the URL in the browser from e.g. http://querona-example:9000 to http://querona-example:4040 where 4040 is the Spark GUI port set in spark.ui.port variable (4040 is the default value).
Spark GUI should open and you should see the query executed:
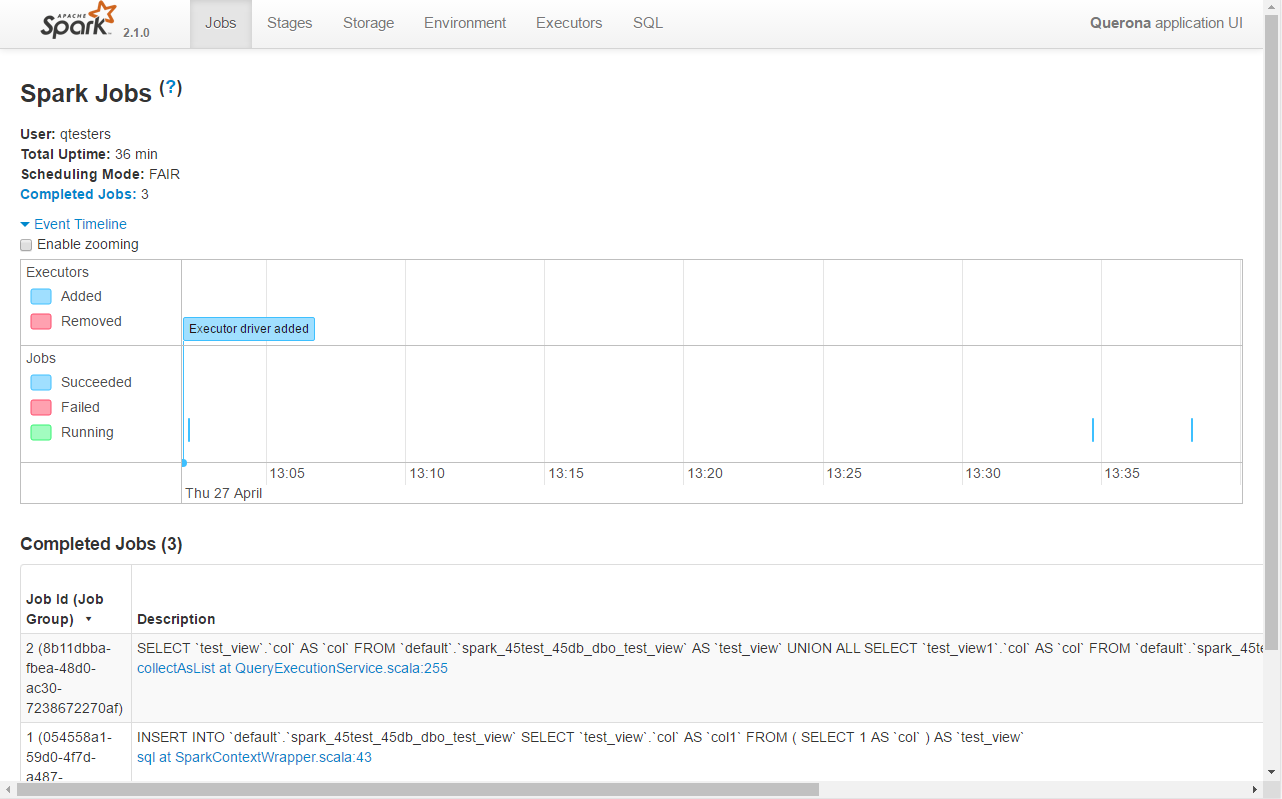
You can click on the tabs to see different jobs and parameters which might be useful for future debugging and optimization.