HDInsight cluster#
For more resource consuming operations it makes sense to use a preconfigured standalone cluster. Once setup you should configure a new Local instance except for the Spark master parameter should be set to the proper URL e.g. spark://HOST:PORT.
If you don’t have a running Spark cluster already in place, then Azure HDInsight may be the solution to quickly get one running.
Querona fully supports HDInsight as the data federation engine.
HDInsight configuration#
To add a new cluster, use the Azure Portal:
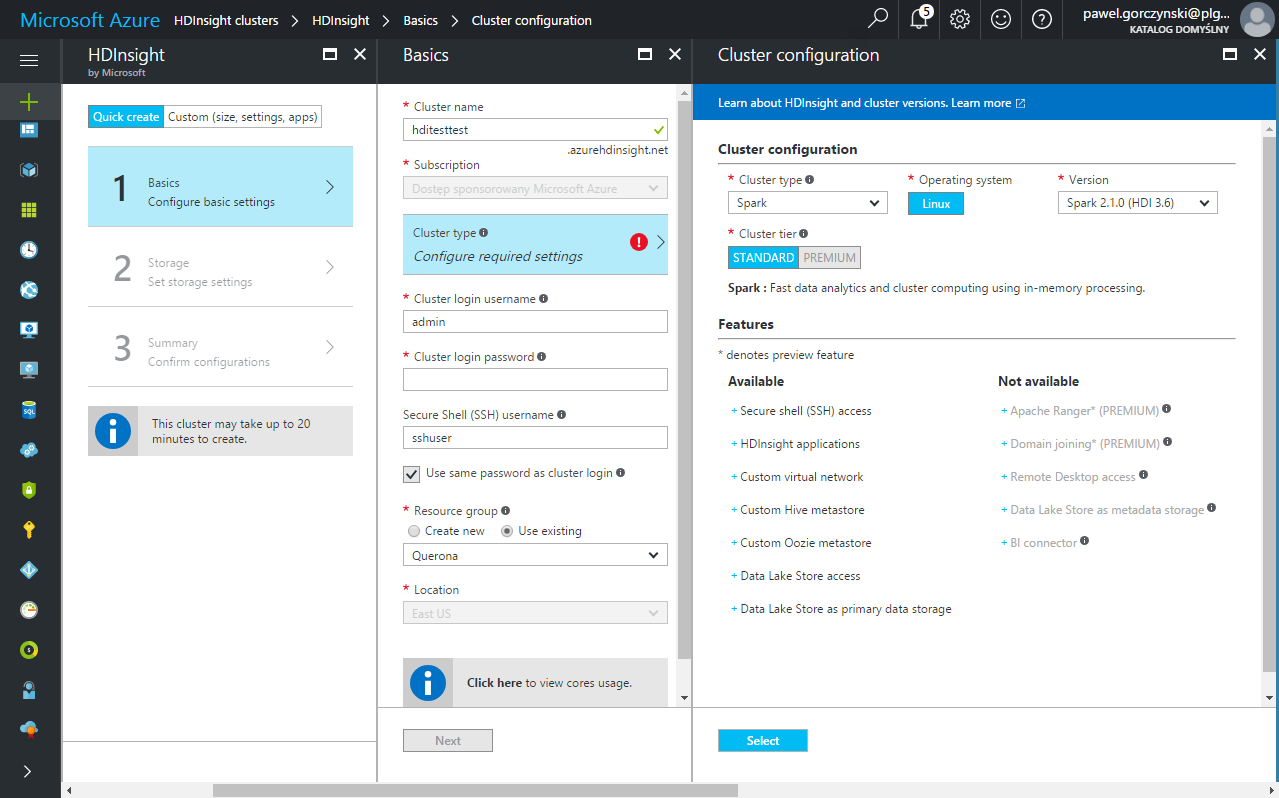
The following table summarizes the important parameters to be defined:
Parameter |
Description |
|---|---|
Cluster login username |
Login that will be used to access Using Ambari |
Cluster login password |
Password that will be used to access Using Ambari |
Secure Shell (SSH) username |
|
Cluster type |
Use “Spark” |
Version |
Spark version - Querona supports Spark from 2.0.0 and newer |
It is important to note that the communication between HDI and Querona is required both ways, meaning the Querona must be able to reach the driver on the querona.driver.port value (default: 8400) and the driver must be able to reach Querona on the TDS port (default: 1200). To make it work, the HDI cluster should be placed in a proper network, meeting these requirements.
Driver deployment#
(further instructions assume that the HDInsight cluster is already configured and running).
The basic idea is similar to Spark Local instance, except the driver is deployed using Azure Portal on all (two) HDInsight head nodes (with failover enabled by default) and submitted with Spark master = master yarn which means that instead of running a new instance we are attaching to the running YARN process.
Building the tarball#
Uploading the driver is done using the HDInsight Script Action mechanism. To do this the driver must be packed in a .tar.gz file and uploaded to an arbitrary publicly visible Azure blob.
The necessary tools and folder structure can be found in the %QUERONA_INSTALL_FOLDER%\HDInsight\version directory.
We recommend copying this folder a local-user location to avoid problems with Windows elevated privileges.
The important step to be done at this point it configuring the primary driver parameters.
Open querona\querona-site.xml with any text editor. The following values are particularly important:
Parameter |
Description |
|---|---|
querona.api.key |
must match the value entered later when creating a connection to the cluster; shouldn’t be left with the default value |
querona.driver.port |
The port the driver will listen on (default: 8400) |
querona.driver.protocol |
The connection protocol - possible values: thrift, http |
querona.ha.enable |
See: Cluster failover |
Additionally a second file log4j.properties contains the Log4J configuration for the Querona driver, which can be tweaked as well.
By default, it logs all data into *./logs* directory separately for each HDInsight head node with TRACE level.
Contrary to the local instance, the logs are not streamed back to the master Querona instance in any way and thus the only way to access them
is logging directly to the given node e.g. by SSH (see: Advanced management and troubleshooting).
Once done, the Build-Tarball.cmd scripts use 7Zip to the tarball and gzip all necessary files. The following line should be adjusted if necessary: set ZIP_EXE=”C:Program Files7-Zip7z.exe”
If everything went fine, a new file like querona21.tar.gz should appear. Now this file together with install-querona-driver-21.sh
must be uploaded to a public Azure blob. You can either do it manually using a tool such as Microsoft Azure Storage Explorer
or use the provided Build-Tarball-and-Upload.ps1 which runs the Build-Tarball.cmd
and then uses the Azure Powershell to upload both files (installation required).
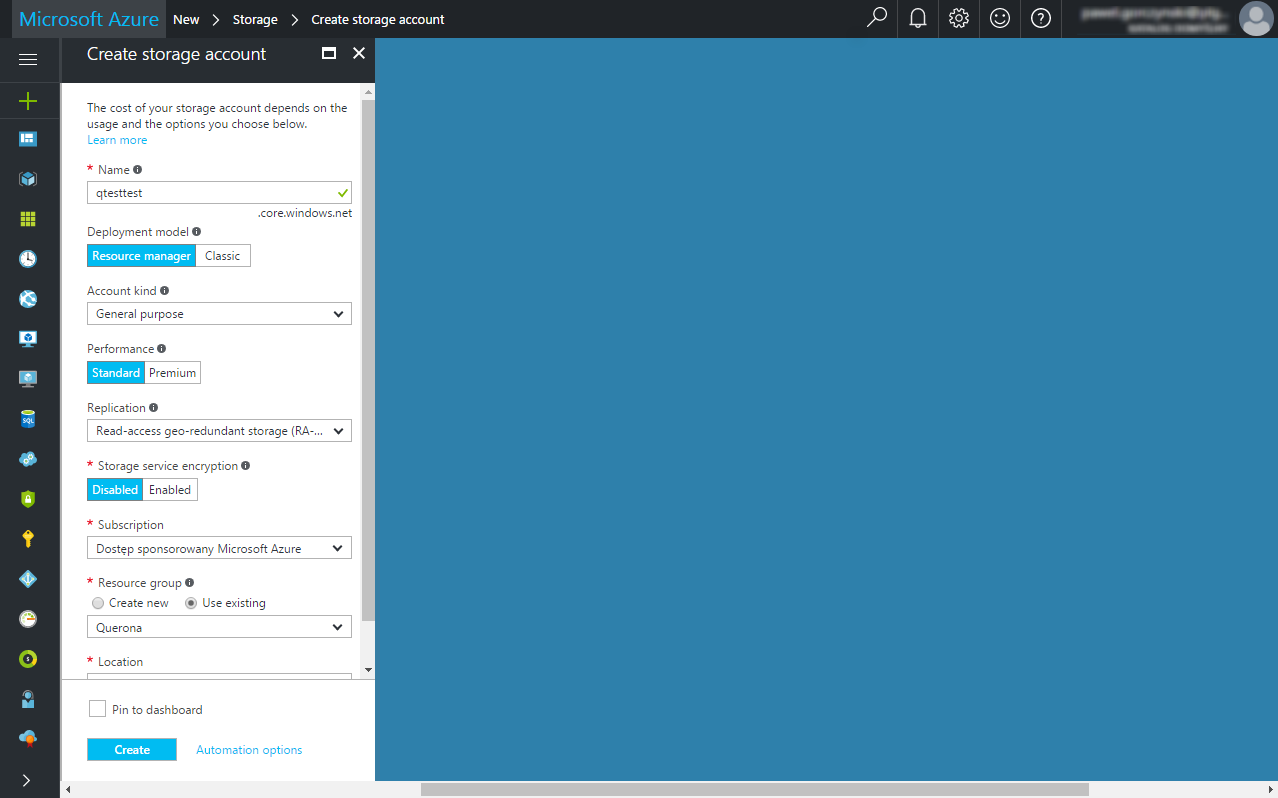
At this point you either have to use an existing or create a new Azure Storage Account using Azure Portal:
Once created, find the new resource to obtain the StorageAccountName and StorageAccountKey:
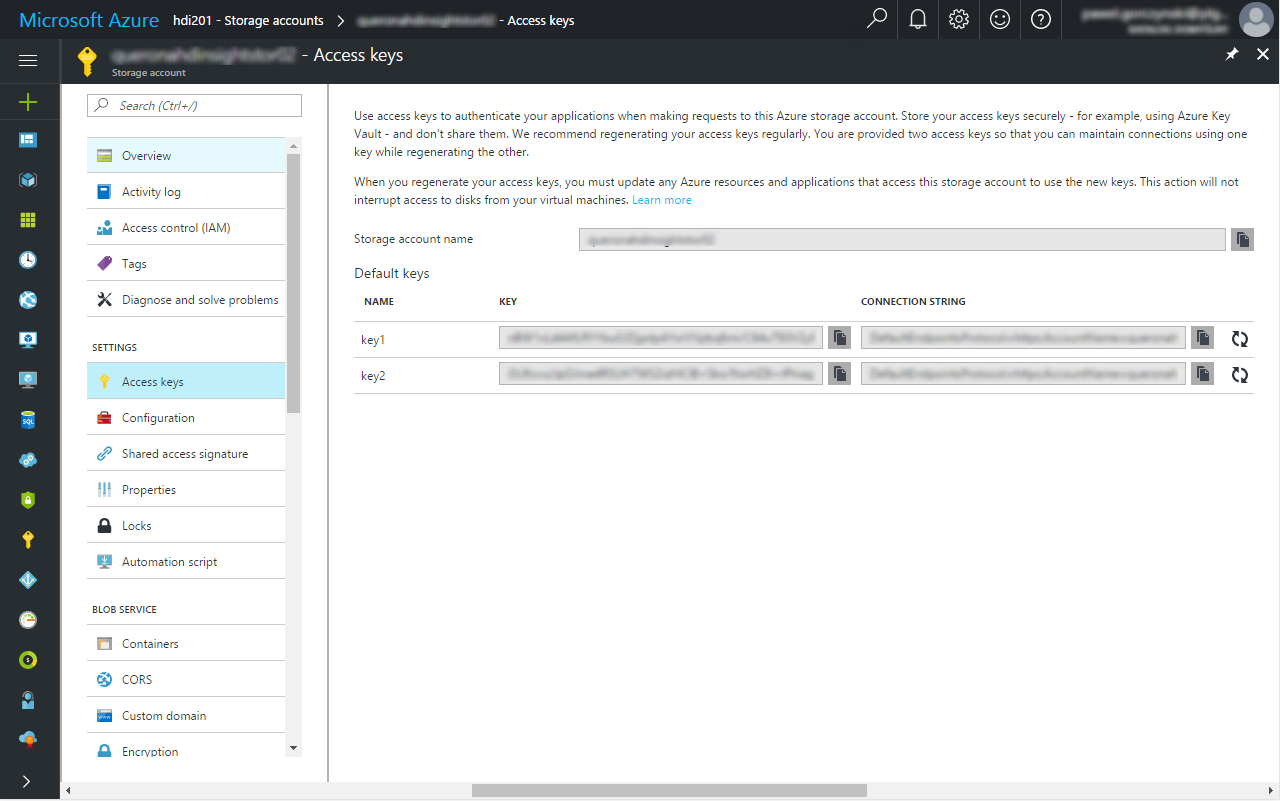
Edit the Build-Tarball-and-Upload.ps1 and copy-paste the values to the correct lines of the file. $ContainerName can be changed as well.
Once run (using Windows Powershell ISE) a progress bar might appear and after several second the outcome should be more or less like the following:
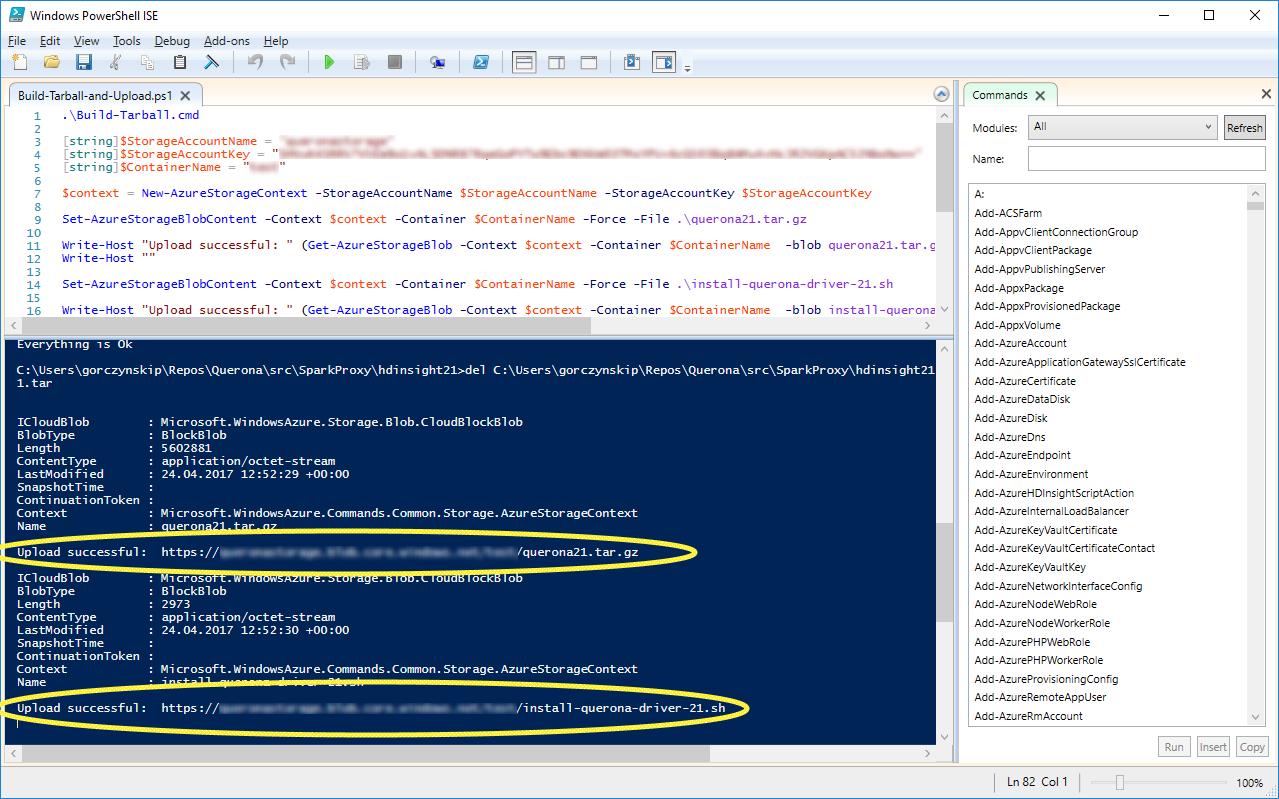
The two highlighted URLs are the final locations of the files. You can copy-paste them in a web browser to make sure they are publicly available (they can be removed after the deployment process).
Running the installation script#
On the HDI cluster management screen please find the Script actions button.
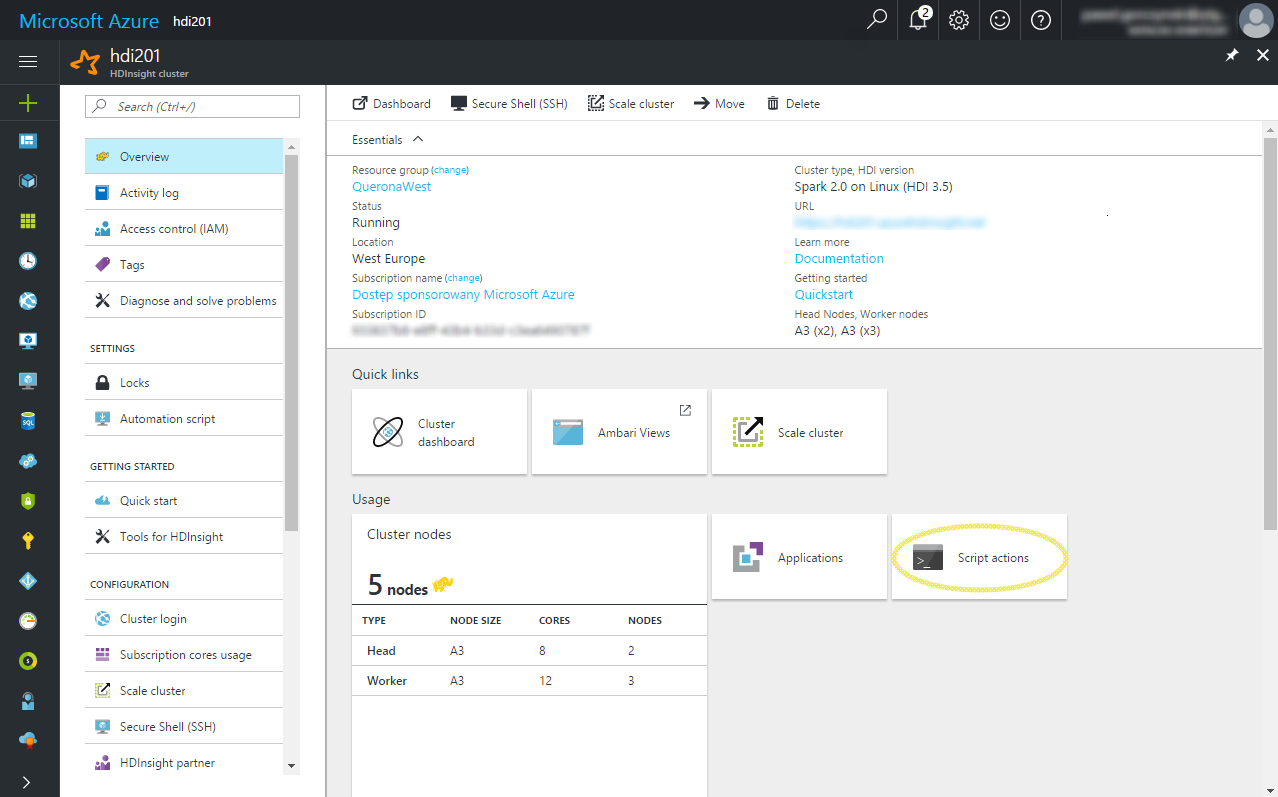
Then click Submit new
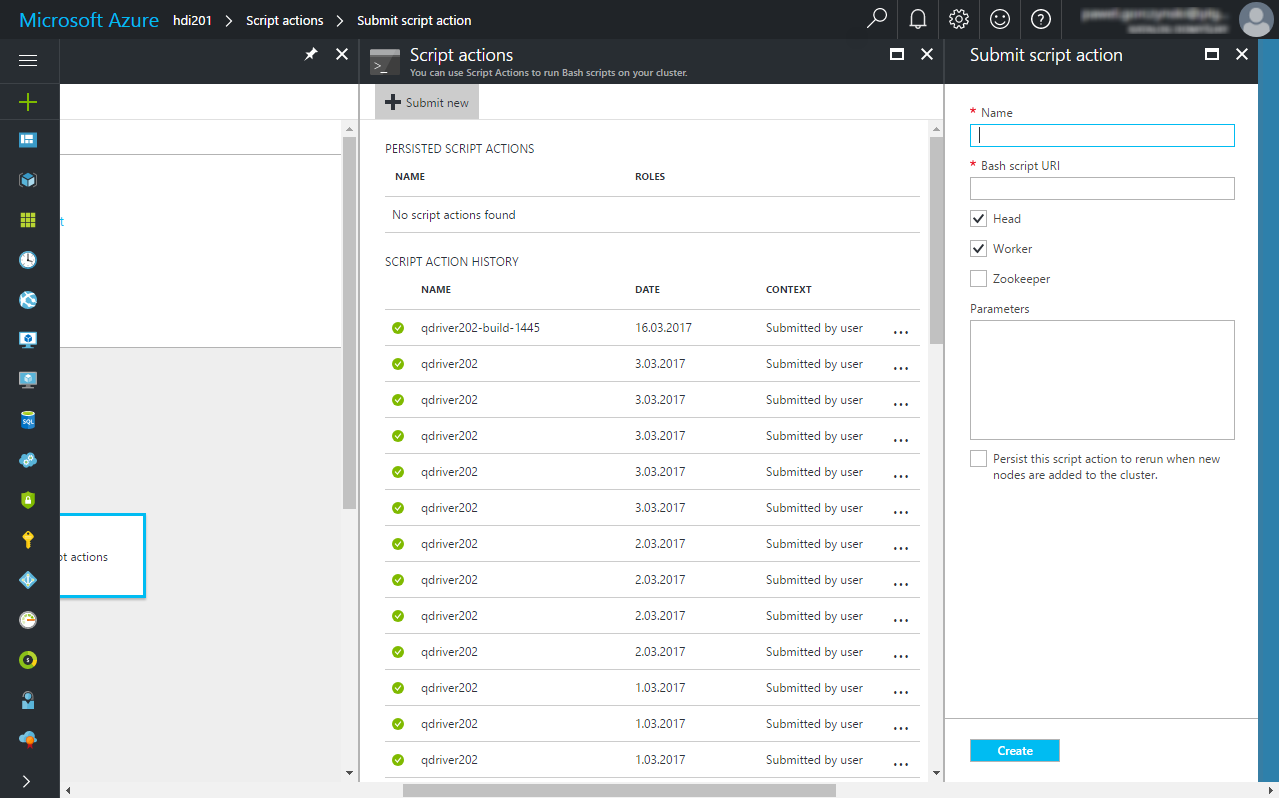
You can see the previous submissions as well - the Resubmit option makes it quite convenient to run the same script again in case you need to e.g. change the parameters.
The following table summarizes the inputs
Parameter |
Description |
|---|---|
Name |
A user-friendly name of the script e.g. qdriver202-build-1445 |
Bash script URI |
URL pointing the install-querona-driver-21.sh the script generated above e.g. https://test-server.blob.core.windows.net/test/install-querona-driver-21.sh |
Head |
Should the script run on head nodes? Check |
Worker |
Should the script run on worker nodes? Uncheck |
Zookeeper |
Should the script run on zookeeper nodes? Uncheck |
Parameters |
Script arguments - see below |
Persist this script action |
This only applies to worker nodes (Uncheck) |
Script arguments should be passed as follows:
- the URL of the .tar.gz generated above
- spark-submit arguments passed in quotes
So the sample field of this value could be https://test-server.blob.core.windows.net/test/querona21.tar.gz “–driver-memory 4g –executor-memory 4g –executor-cores 1”
Clicking Create should submit the script for execution. Usually, it takes a few minutes for the script to execute. Failures usually occur faster.
Successful execution doesn’t always mean everything went fine.. Go through the next chapter to verify.
Using Ambari#
One of the properties on the cluster Dashboard is the URL e.g. https://test-server.azurehdinsight.net. Clicking this URL opens Ambari - a graphical environment used for monitoring the cluster.
Apart from many different functions, you can also monitor the execution of submitted Script actions. They can be accessed during and after execution by clicking in the upper right menu:
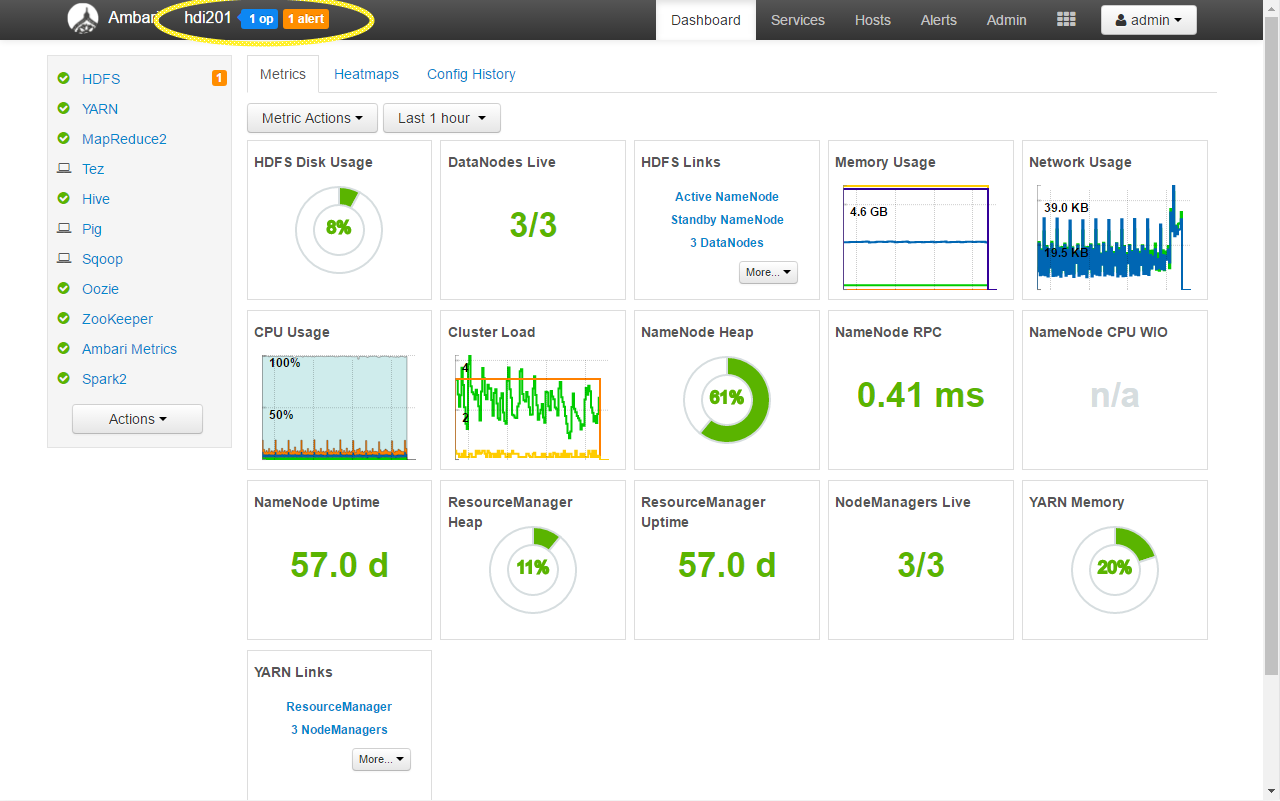
This brings up the Background operations window
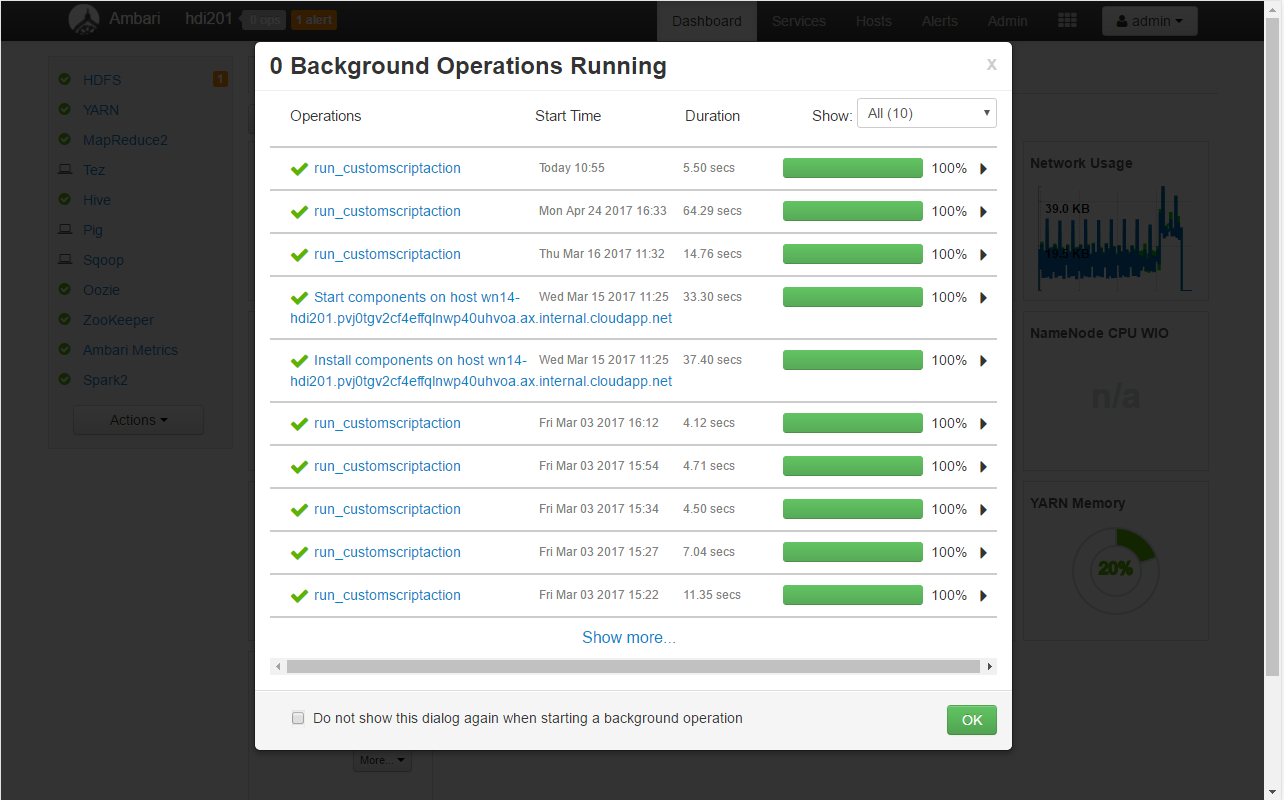
Drilling down will allow to access the execution logs for every requested cluster node (both head nodes in this case):
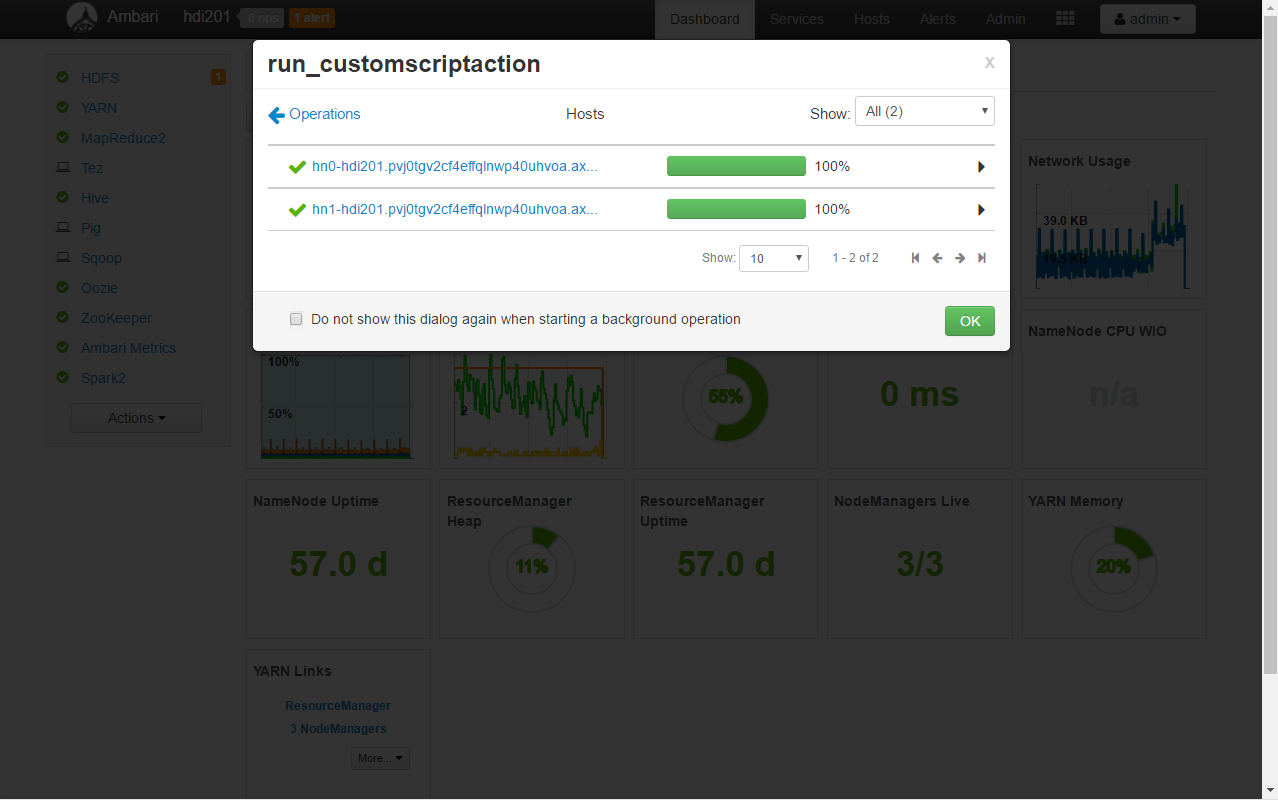
If everything went fine the logs for every head node should look more or less like the following:
stderr:
--2017-04-25 09:08:37-- https://test-server.blob.core.windows.net/test/querona21.tar.gz
Resolving test-server.blob.core.windows.net (test-server.blob.core.windows.net)... 13.79.176.56
Connecting to test-server.blob.core.windows.net (test-server.blob.core.windows.net)|13.79.176.56|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 5602881 (5.3M) [application/octet-stream]
Saving to: /tmp/querona/querona21.tar.gz
0K .......... .......... .......... .......... .......... 0% 1.11M 5s
50K .......... .......... .......... .......... .......... 1% 144M 2s
100K .......... .......... .......... .......... .......... 2% 2.19M 2s
.
.
.
5300K .......... .......... .......... .......... .......... 97% 178M 0s
5350K .......... .......... .......... .......... .......... 98% 110M 0s
5400K .......... .......... .......... .......... .......... 99% 169M 0s
5450K .......... .......... . 100% 250M=0.3s
2017-04-25 09:08:37 (17.2 MB/s) - /tmp/querona/querona21.tar.gz saved [5602881/5602881]
Starting |Product| install script on hn0-hdi201.pvj0tgv2cf4effqlnwp40uhvoa.ax.internal.cloudapp.net, OS VERSION: 16.04
Removing |Product| installation and tmp folder
Downloading |Product| tar file
Unzipping |Product|
querona/
querona/conf/
querona/init/
querona/init/ojdbc6.jar
querona/init/querona.conf
querona/log4j.properties
querona/querona-site.xml
querona/querona.spark.driver-1.0-spark-2.1.0.jar
querona/run-driver.sh
Making |Product| a service and starting
Using systemd configuration
('Start downloading script locally: ', u'https://test-server.blob.core.windows.net/test/install-querona-driver-21.sh')
Fromdos line ending conversion successful
Custom script executed successfully
Removing temp location of the script
Command completed successfully!
The last thing we need to note here is the head node IP addresses we will need them in a minute to connect to the driver. These can be found in the Hosts tab in Ambari:
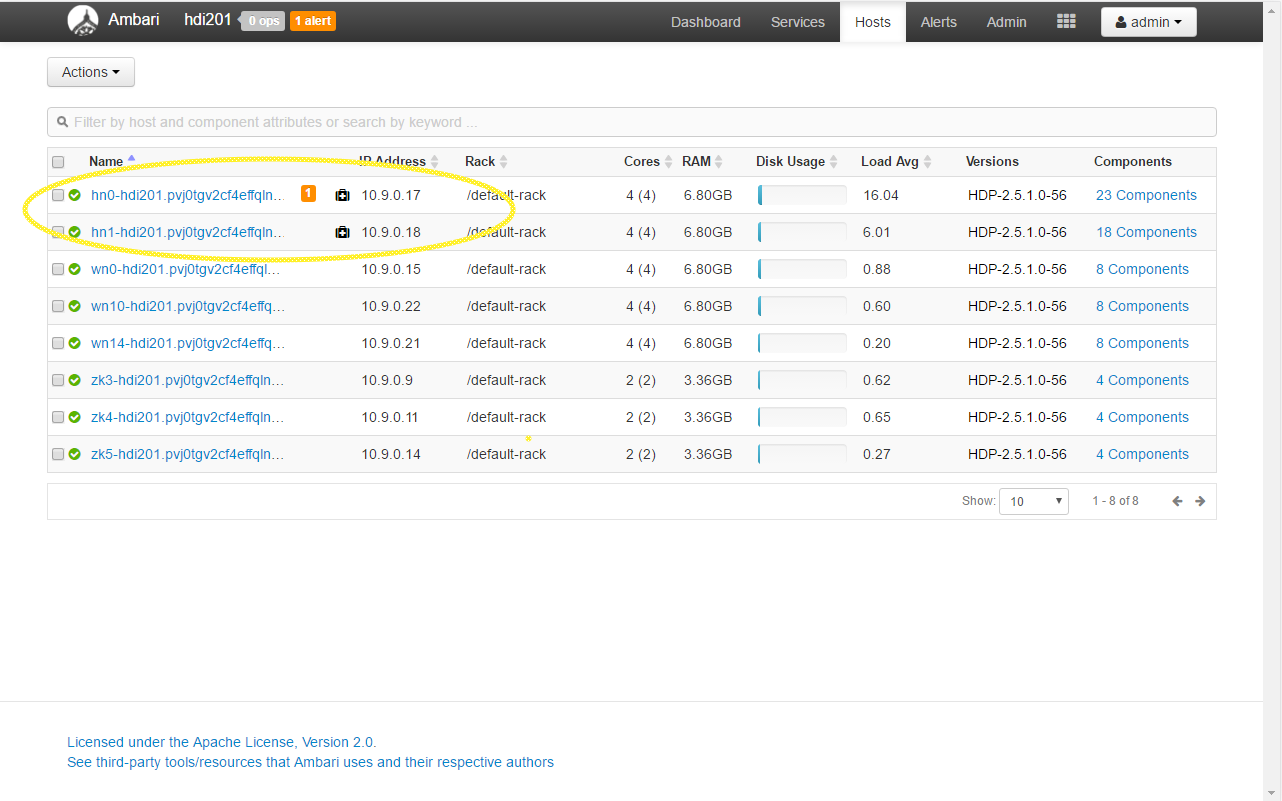
At this point, we can try to add a new Spark connection.
Connecting to HDInsight#
The recommended way to start is to the use the predefined connection template called azure_spark_conn_template.
The following table summarizes the differences in connection parameter semantics compared to local instance connection:
Parameter |
Description |
Default value |
|---|---|---|
Host:Port |
CSV-list all local head-node IPs here e.g. 10.9.0.17:8400,10.9.0.18:8400 |
localhost:8400 |
Protocol |
Must match the one defined in querona-site.xml |
Thrift |
Spark dialect |
It depends on the used HDI version. 2.0 is recommended for new clusters. |
|
Driver API key |
Must match the one defined in querona-site.xml |
querona-key |
Reverse connection host address |
An IP address of Querona instance that the driver will use for reverse connections. Must be reachable from both head nodes. |
|
Node connection timeout |
The timeout used for waiting for each cluster node to respond. See: Cluster failover |
10s |
Cluster initialization timeout |
Since HDI cluster make take up to a few minutes to boot it’s recommended to increase the default value e.g. to 180s |
30s |
Scheduler pools#
Spark variables#
Any properties regarding file system folders shouldn’t be set to avoid errors.
spark.ui.port is not used - read below.
Hive configuration#
Any properties regarding file system folders shouldn’t be set to avoid errors.
Connection test and Spark validation#
Once configured, the same steps as for local instance can be done to ensure Spark was initialized. But since on HDInsight the driver is deployed a YARN client accessing the Spark GUI in done differently:
Under Ambari click .
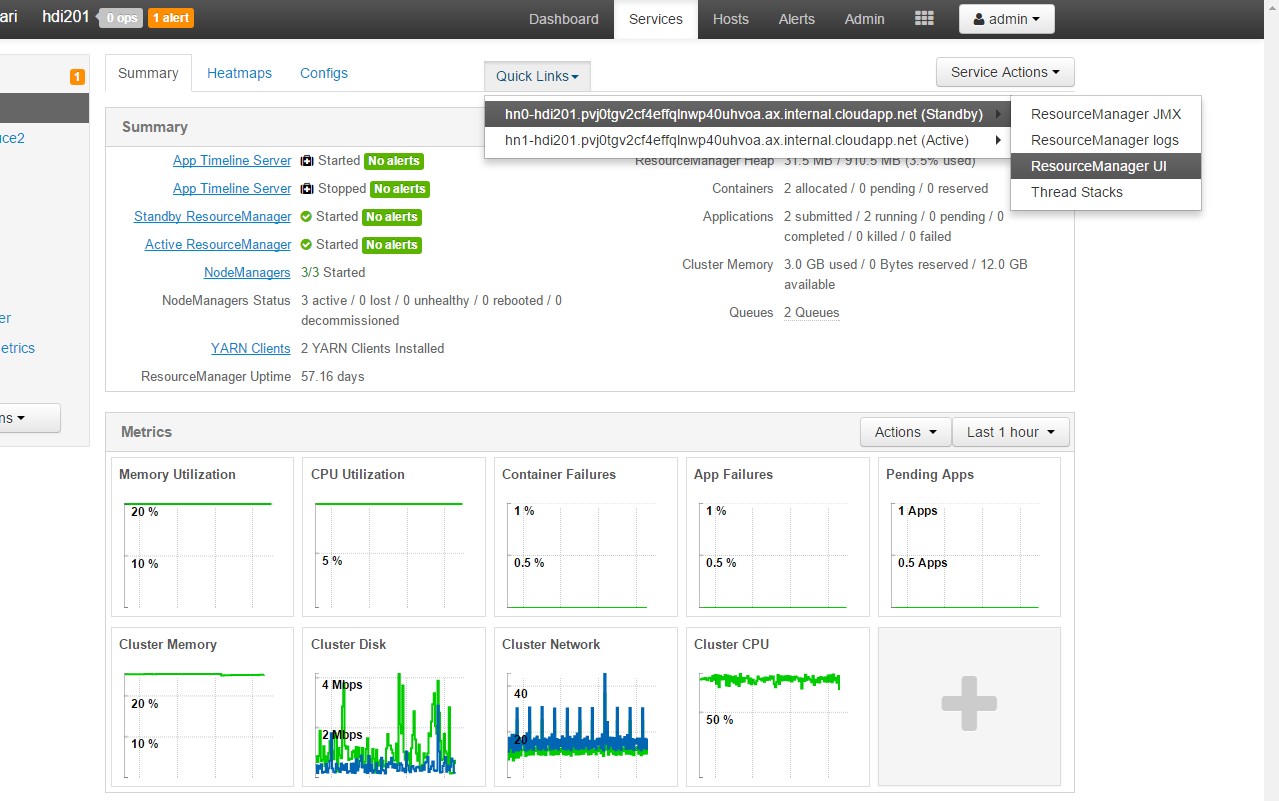
This will open the YARN UI. Since there’s only one instance per cluster, it doesn’t matter which node you select.
The same UI is also available directly via URL like <https://test-server.azurehdinsight.net/yarnui/hn/cluster>.
If initialization was trigger our application should first appear on the SUBMITTED list and then move to RUNNING:
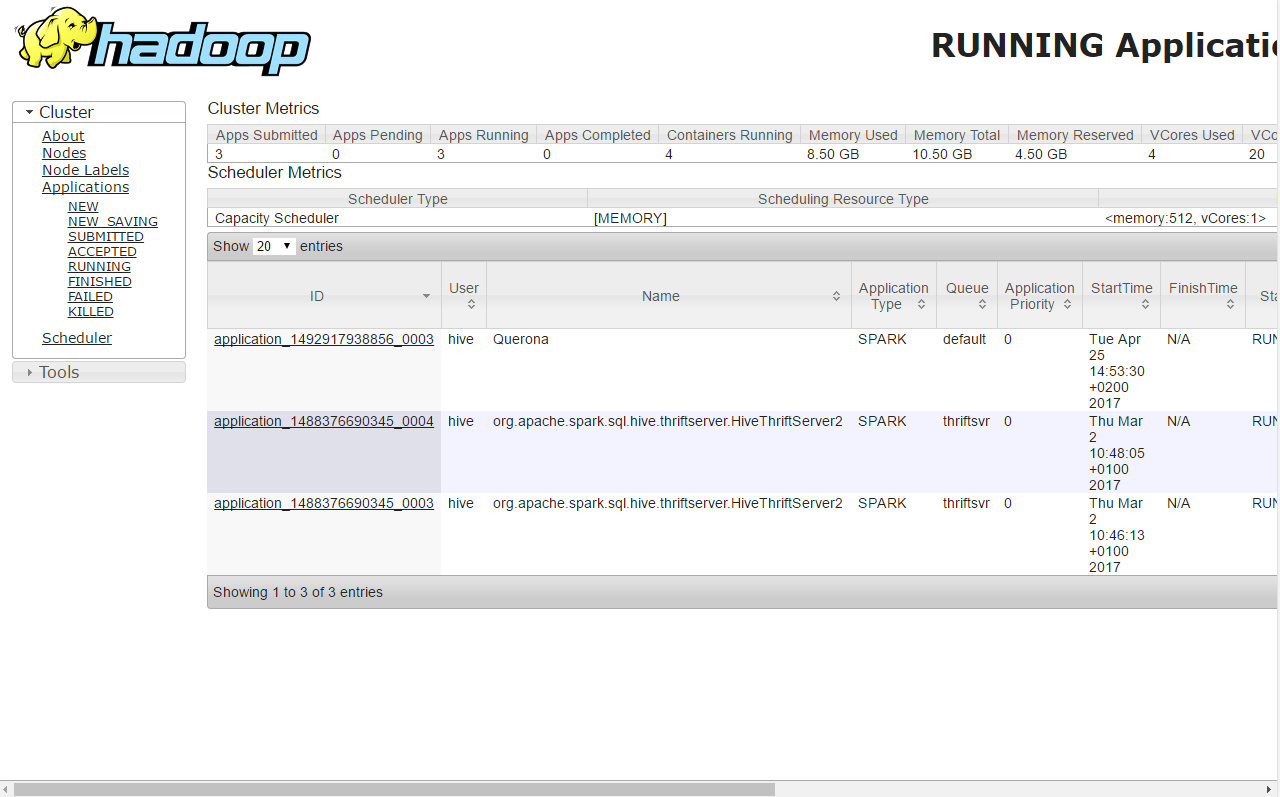
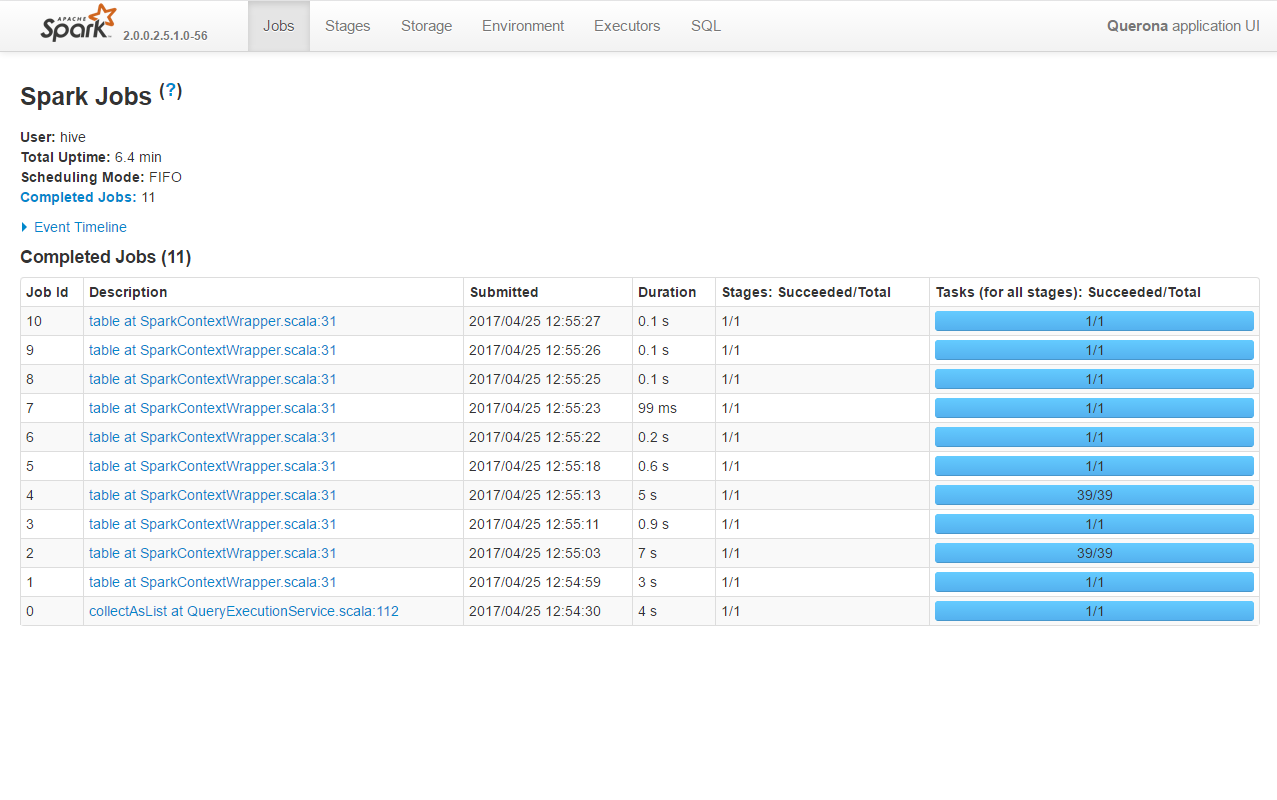
Clicking the ID shows the details screen and from there Tracking URL: ApplicationMaster link leads to the Spark UI:
Advanced management and troubleshooting#
Using WinSCP to view the folder structure#
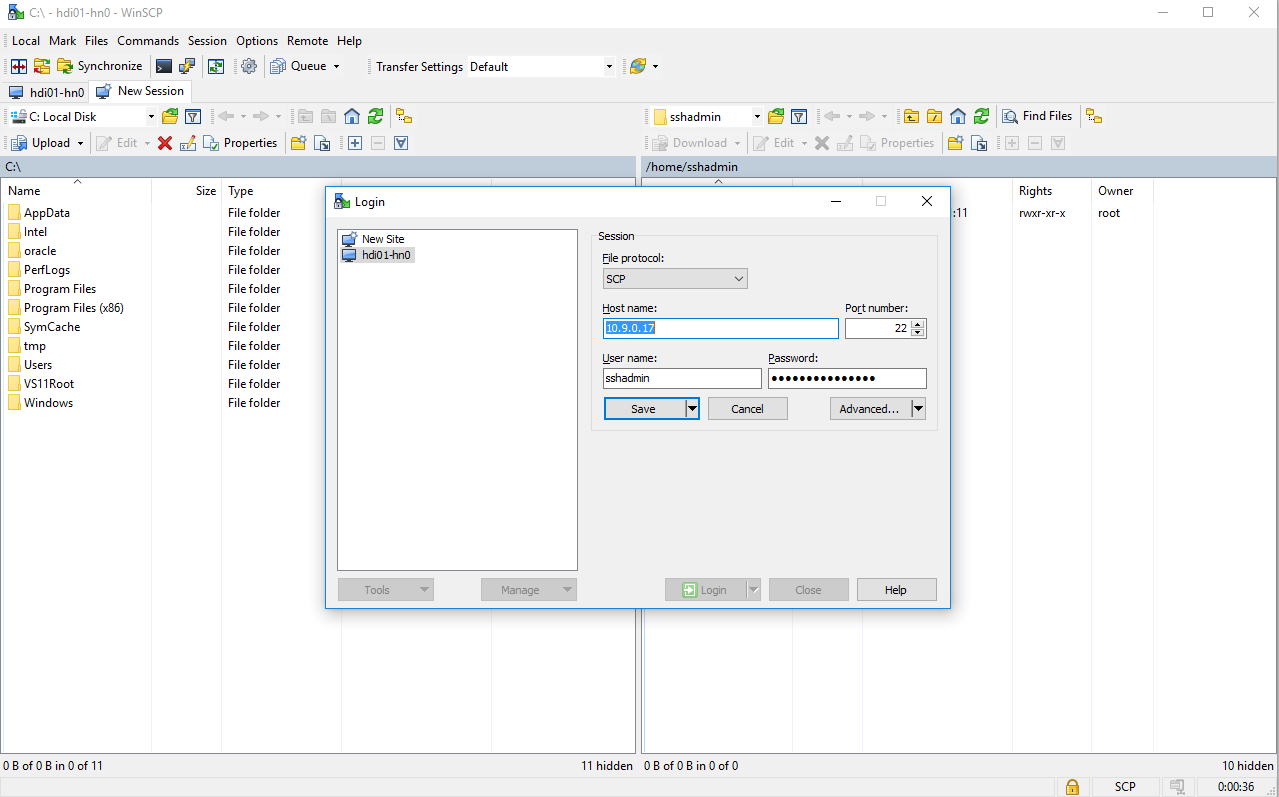
All HDI nodes are Linux-based machines which enable easy management. As an example, we are using WinSCP. The following screenshot shows a sample connection configuration. The Host name field contains the IP address of the first head node.
Navigating to /usr/share/querona will take you to the installation folder:
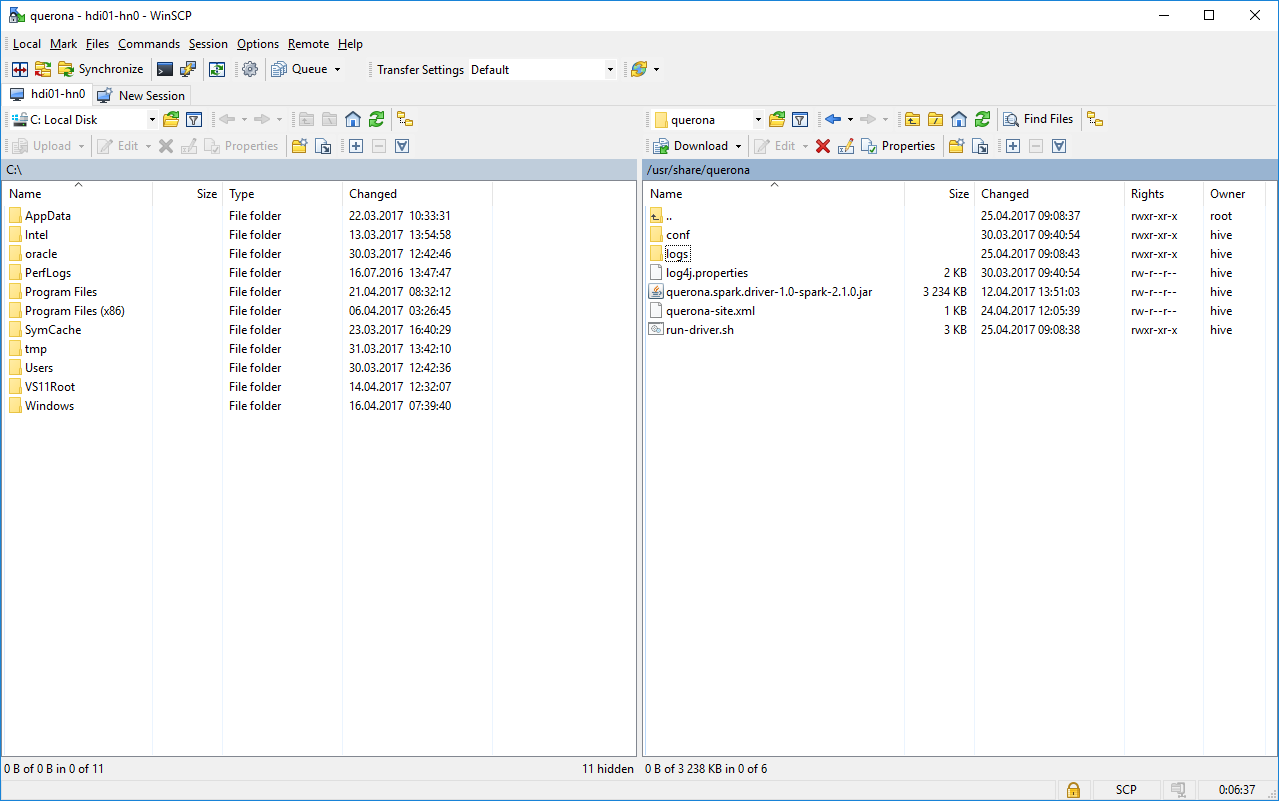
the logs folder contains the driver log files,
querona-site.xml can be edited here as well, but service restart is required,
log4j.properties can be used to adjust the logging levels,
Note that we are on a single of two head nodes, so any action must be taken separately for each node. This applies to log files as well.
Using Putty to manage the service#
Together with WinSCP, we recommend installing Putty. Then directly from WinSCP we can open a new Putty session and login to the node using CLI.
Starting from HDI 2.0 the driver is run a standard systemd deamon so we can use systemctl to manage the querona service.
e.g. running systemctl status querona should print something like:
querona.service - querona service
Loaded: loaded (/etc/systemd/system/querona.service; enabled; vendor preset: enabled)
Active: active (running) since Tue 2017-04-25 09:08:38 UTC; 3h 19min ago
Main PID: 37703 (bash)
Tasks: 20
Memory: 112.8M
CPU: 12.974s
CGroup: /system.slice/querona.service
├─37703 bash /usr/share/querona/run-driver.sh
└─37708 /usr/lib/jvm/java-8-openjdk-amd64/bin/java -Dhdp.version=2.5.1.0-56 -cp /usr/hdp/current/hive-server2/lib/sqljdbc41.jar:/usr/share/querona
Apr 25 09:08:44 hn0-hdi201 run-driver.sh[37703]: Starting conductor
Apr 25 09:08:44 hn0-hdi201 run-driver.sh[37703]: 17/04/25 09:08:44 INFO AppConductor: HA is enabled, attempting to start failover service and join leader ele
Apr 25 09:08:44 hn0-hdi201 run-driver.sh[37703]: 17/04/25 09:08:44 INFO AppConductor: Changing NodeState state to: WaitingLeaderResult
Apr 25 09:08:44 hn0-hdi201 run-driver.sh[37703]: 17/04/25 09:08:44 INFO FailoverService: Starting failover monitoring - path: /querona-leader-election time
Apr 25 09:08:44 hn0-hdi201 run-driver.sh[37703]: 17/04/25 09:08:44 INFO ActiveStandbyElector: Session connected.
Apr 25 09:08:44 hn0-hdi201 run-driver.sh[37703]: 17/04/25 09:08:44 INFO ActiveStandbyElector: Successfully created /querona-leader-election in ZK.
Apr 25 09:08:44 hn0-hdi201 run-driver.sh[37703]: 17/04/25 09:08:44 INFO FailoverService: Joining election, my data: 10.9.0.17:8400
Apr 25 09:08:44 hn0-hdi201 run-driver.sh[37703]: 17/04/25 09:08:44 INFO QueronaServer: starting thrift server on port 8400
Apr 25 09:08:44 hn0-hdi201 run-driver.sh[37703]: 17/04/25 09:08:44 INFO AppConductor: Releasing Spark
Apr 25 09:08:44 hn0-hdi201 run-driver.sh[37703]: 17/04/25 09:08:44 INFO AppConductor: Changing NodeState state to: Standby
sudo systemctl restart querona can be used in case of serious problems.
Cluster failover#
Querona driver supports automatic failover using Apache Zookeeper.
To make it work the driver has to have at least two instances running and the Zookeeper service must be available. There are two parameters in the querona-site.xml regarding this:
Parameter |
Description |
|---|---|
querona.ha.enable |
Enables/disables failover. Enabled by default in the HDInsight, disabled for local instances. Possible values: true, false. |
ha.zookeeper.quorum |
A CSV-list of a server:port values of Zookeeper servers. In HDInsight the value is already provided by the environment and is not required. |
Once started, all driver instances will participate in a leader election and choose the active node. All other nodes will continue to listen for incoming connection but will transition to StandBy state.
Now when adding a new Spark connection, all servers should be entered in the Host:Port configuration field. Querona will try to find the active node using round-robin. Node connection timeout determines the wait time per each node. If an active node is not found within the Cluster initialization timeout the connection will fail.
If for any reason one of the nodes fails, a new election will start automatically. Any queries that were halted by the node failure, will be rerun automatically once a new active node is found.